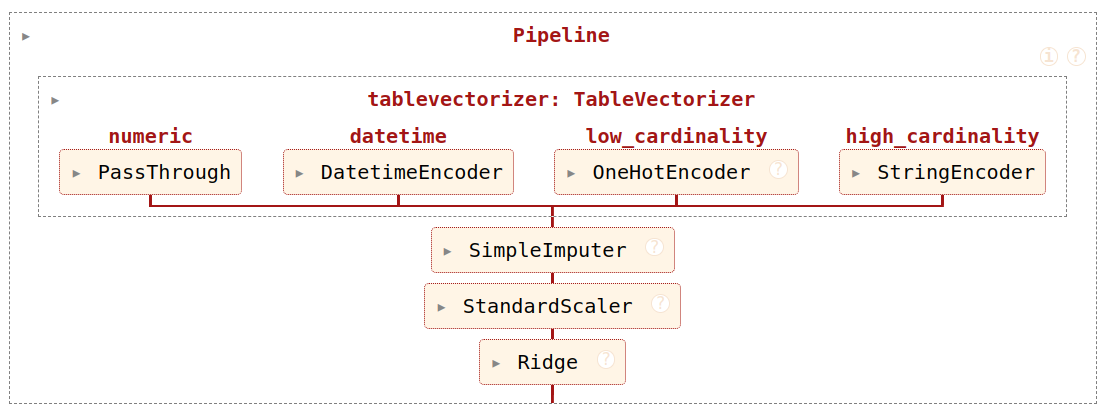
import pandas as pd
import numpy as np
data = {
"Int": [2, 3, 2], # Multiple unique values
"Const str": ["x", "x", "x"], # Single unique value
"Str": ["foo", "bar", "baz"], # Multiple unique values
"All nan": [np.nan, np.nan, np.nan], # All missing values
"All empty": ["", "", ""], # All empty strings
"Date": ["01 Jan 2023", "02 Jan 2023", "03 Jan 2023"],
}
df_pd = pd.DataFrame(data)
display(df_pd)| Int | Const str | Str | All nan | All empty | Date | |
|---|---|---|---|---|---|---|
| 0 | 2 | x | foo | NaN | 01 Jan 2023 | |
| 1 | 3 | x | bar | NaN | 02 Jan 2023 | |
| 2 | 2 | x | baz | NaN | 03 Jan 2023 |