Feature engineering with skrub
Under the hood of the TableVectorizer and tabular_pipeline
Both the TableVectorizer and the tabular_pipeline rely on skrub encoders do feature engineering:
- categorical features need to be converted into numbers
- datetime features need to be split in datetime parts
- numeric feature need to be scaled
In this chapter we will cover the relevant skrub transformers in more detail
Safe scaling of numerical features
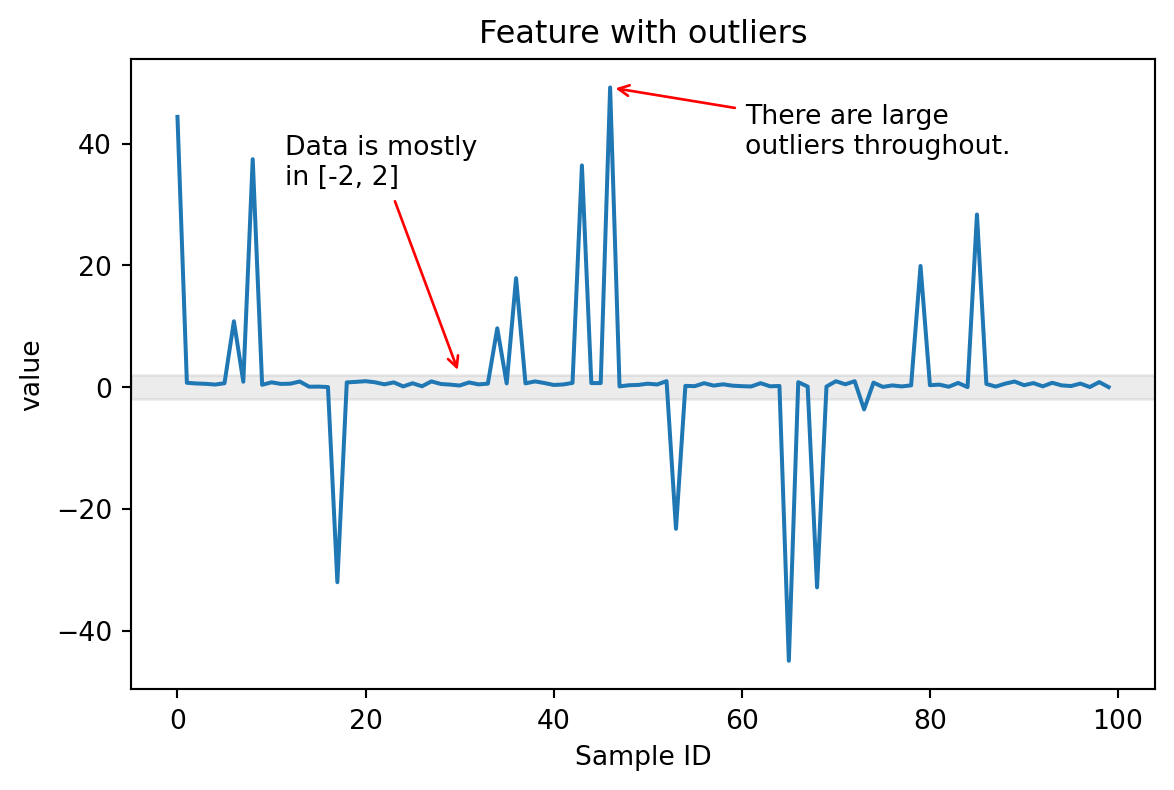
Consider a situation where a numerical feature includes large outliers.
Most values are in range [-2, 2], but some outliers are in [-40, 40]:
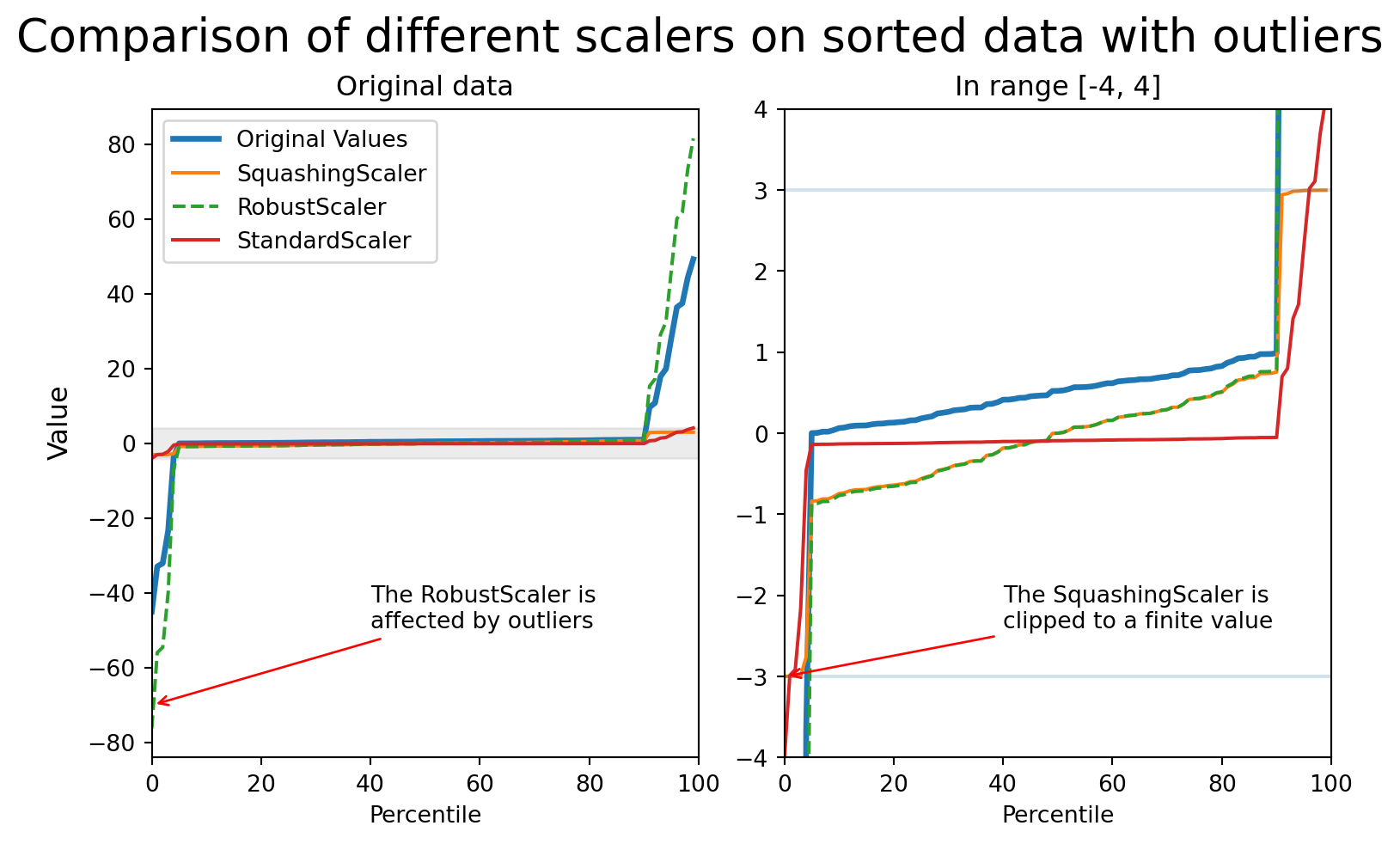
StandardScaler Problems
- Uses mean and standard deviation
- Outliers make these statistics unreliable
- Scaling factor becomes too small
- Inliers get compressed into narrow range
RobustScaler
- Uses percentiles (25th, 75th) instead of mean/std
- More resistant to outliers
- But doesn’t bound output values
- Extreme outliers still have large scaled values
SquashingScaler: Best Approach
Smart outlier handling in skrub:
Comparing the scalers
How SquashingScaler Works
- Center the median to 0
- Fill constant columns with 0s
- Apply a smooth squashing function
- Constrain output to [-3, 3] (default)
- Map infinite values to boundaries
- Keep NaN values unchanged
In summary:
Advantages:
- Outlier-resistant: Inliers unaffected by outliers
- Bounded output: Predictable range ideal for neural networks
- Handles edge cases: Works with infinite values, constant columns
- Preserves NaN: Missing values stay unchanged
Disadvantages:
- Non-invertible: Cannot perfectly reverse transformation
Encoding categorical features
Machine learning models need numeric input, but we have:
- Names: “Alice”, “Bob”
- Occupations: “engineer”, “teacher”
- Locations: “NYC”, “LA”
- Text: reviews, tweets, comments… …
How to convert these features to numbers?
One-Hot Encoding
Creates binary indicator columns:
Pros: Intuitive, works well for few categories Cons: Explodes with many categories, creates sparse matrices, leads to overfitting, worsens model interpretability
The Challenge: High-Cardinality Features
What if you have 1000+ unique values (IDs, free text)?
How skrub deals with categorical features
Skrub implements four different strategies:
StringEncoderTextEncoderMinHashEncoderGapEncoder
StringEncoder: Best All-Rounder
- Uses TF-IDF + SVD for dimensionality reduction
- Fixed output dimension (n_components)
- Fast and robust
- Not very good with free-flowing text
- Default in both
TableVectorizerandtabular_pipeline
TextEncoder: For Natural Language
- Captures semantic meaning, works very well on text
- Very slow on CPU, requires sentence-transformers (heavy dependency)
Encoder Comparison
| Encoder | Speed | Performance | Interpretability | Use Case |
|---|---|---|---|---|
| OneHot | Fast | Good | High | Low cardinality |
| StringEncoder | Fast | Good | Low | Default choice |
| TextEncoder | Slow | Excellent | Medium | Real text data |
| MinHashEncoder | Very Fast | Fair | Low | Quick prototyping |
| GapEncoder | Slow | Good | High | Interpretability needed |
In summary
- Use
OneHotEncoderfor < 40 unique values - Use
StringEncoderfor high-cardinality - Use
TextEncoderfor true natural language
Encoding datetimes
Datetimes come in many formats:
- “2023-01-03” (ISO format)
- “03/01/2023” (EU format)
- “January 3, 2023” (text)
- “03 Jan 2023” (custom)
Correct parsing is essential for feature extraction.
Converting Strings to Datetime
ToDatetime: Single column transformer with format guessing:
| dates | |
|---|---|
| 0 | 2023-01-03 |
| 1 | 2023-02-15 |
Cleaner: Same machinery:
| dates | |
|---|---|
| 0 | 2023-01-03 |
| 1 | 2023-02-15 |
Both objects can take a datetime_format if known.
Extracting Datetime Features
Datetimes must be converted to numerical features:
df_dt["year"] = df_dt["dates"].dt.year
df_dt["month"] = df_dt["dates"].dt.month
df_dt["day"] = df_dt["dates"].dt.day
df_dt["weekday"] = df_dt["dates"].dt.weekday
df_dt["day_of_year"] = df_dt["dates"].dt.day_of_year
df_dt["total_seconds"] = (df_dt["dates"] - pd.Timestamp("1970-01-01")) // pd.Timedelta('1s')
df_dt| dates | year | month | day | weekday | day_of_year | total_seconds | |
|---|---|---|---|---|---|---|---|
| 0 | 2023-01-03 | 2023 | 1 | 3 | 1 | 3 | 1672704000 |
| 1 | 2023-02-15 | 2023 | 2 | 15 | 2 | 46 | 1676419200 |
Simpler with DatetimeEncoder
| dates_year | dates_month | dates_day | dates_total_seconds | dates_weekday | dates_day_of_year | |
|---|---|---|---|---|---|---|
| 0 | 2023.0 | 1.0 | 3.0 | 1.672704e+09 | 2.0 | 3.0 |
| 1 | 2023.0 | 2.0 | 15.0 | 1.676419e+09 | 3.0 | 46.0 |
Periodic Features
Cyclical patterns need special handling:
- Day of week: 0-6, but 0 and 6 are close
- Month: 1-12, but 12 and 1 are close
- Hour: 0-23, but 23 and 0 are close
Circular (Sin/Cos) Encoding
Or with DatetimeEncoder:
| dates_year | dates_total_seconds | dates_month_circular_0 | dates_month_circular_1 | dates_day_circular_0 | dates_day_circular_1 | |
|---|---|---|---|---|---|---|
| 0 | 2023.0 | 1.672704e+09 | 0.500000 | 0.866025 | 5.877853e-01 | 0.809017 |
| 1 | 2023.0 | 1.676419e+09 | 0.866025 | 0.500000 | 1.224647e-16 | -1.000000 |
Spline Encoding Alternative
| dates_year | dates_total_seconds | dates_month_spline_00 | dates_month_spline_01 | dates_month_spline_02 | dates_month_spline_03 | dates_month_spline_04 | dates_month_spline_05 | dates_month_spline_06 | dates_month_spline_07 | dates_month_spline_08 | dates_month_spline_09 | dates_month_spline_10 | dates_month_spline_11 | dates_day_spline_0 | dates_day_spline_1 | dates_day_spline_2 | dates_day_spline_3 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 2023.0 | 1.672704e+09 | 0.0 | 0.166667 | 0.666667 | 0.166667 | 0.000000 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.036000 | 0.538667 | 0.414667 | 0.010667 |
| 1 | 2023.0 | 1.676419e+09 | 0.0 | 0.000000 | 0.166667 | 0.666667 | 0.166667 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.0 | 0.166667 | 0.000000 | 0.166667 | 0.666667 |
Example: spline periodic features
example of periodic features generated with splines
What we have seen in this chapter
SqushingScalerprovides robust and smooth scaling of numeric values with outliers- The
StringEncoderis a good default for encoding strings - The
TextEncoderworks well on meaningful text data - Use
ToDatetimeorCleanerto parse string dates DatetimeEncoderextracts useful features, including periodic features