
fetch_credit_fraud#
- skrub.datasets.fetch_credit_fraud(data_home=None, split='train')[source]#
Fetch the credit fraud dataset (classification) available at skrub-data/skrub-data-files
This is an imbalanced binary classification use-case. This dataset consists of two tables:
baskets, containing the binary fraud target label
products
Baskets contain at least one product each, so aggregation then joining operations are required to build a design matrix. Size on disk: 16MB.
- Parameters:
- Returns:
- bunchsklearn.utils.Bunch
A dictionary-like object with the following keys:
baskets: pd.DataFrame, table containing baskets ID and target.
Shape: (92790, 2) -
product: pd.DataFrame, table containing features about productscontained in baskets. Shape: (163357, 7)
metadata: a dictionary containing the name, description, source and target
Gallery examples#
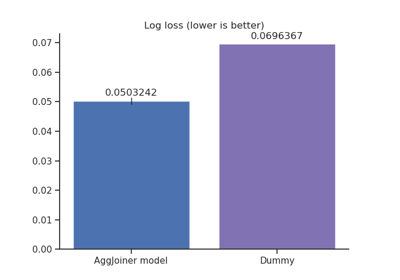

Multiples tables: building machine learning pipelines with DataOps