
Handling datetimes: parsing from strings and encoding as numbers#
Depending on the input data, timestamps and dates can cause issues, or require
specific parsing. For example, reading input data stored in csv format results
in datetime columns that are treated as strings.
In such cases, parsing columns that contain timestamps or dates so that they are treated as datetime objects allows to make use of advanced functionalities available in the standard Python library, Pandas and Polars.
Skrub provides objects that help with parsing such data (ToDatetime), as well
as the DatetimeEncoder, a datetime-specific encoder that feature engineers
datetime columns.
Parsing Datetime Strings with ToDatetime#
Skrub provides helpers to parse datetime string columns automatically:
The
ToDatetimetransformer learns a mapping between columns and their formats. It then applies this mapping during the transform step.The
to_datetime()function applies theToDatetimetransformer to all columns in the dataframe, and tries to parse them as datetimes. The format can be inferred or user-specified with theformatargument.
>>> import pandas as pd
>>> s = pd.Series(["2024-05-05T13:17:52", None, "2024-05-07T13:17:52"], name="when")
>>> s
0 2024-05-05T13:17:52
1 ...
2 2024-05-07T13:17:52
Name: when, dtype: ...
>>> from skrub import ToDatetime
>>> to_dt = ToDatetime()
>>> to_dt.fit_transform(s)
0 2024-05-05 13:17:52
1 NaT
2 2024-05-07 13:17:52
Name: when, dtype: datetime64[...]
The attributes format_, output_dtype_, output_time_zone_
record information about the conversion result.
>>> to_dt.format_
'%Y-%m-%dT%H:%M:%S'
>>> to_dt.output_dtype_
dtype('<M8[...]')
>>> to_dt.output_time_zone_ is None
True
Once ToDatetime was successfully fitted, transform will always try to
parse datetimes with the same format and output the same dtype. Entries that
fail to be converted result in a null value:
>>> s = pd.Series(["2024-05-05T13:17:52", None, "2024-05-07T13:17:52"], name="when")
>>> to_dt = ToDatetime().fit(s)
>>> to_dt.transform(s)
0 2024-05-05 13:17:52
1 NaT
2 2024-05-07 13:17:52
Name: when, dtype: datetime64[...]
>>> s = pd.Series(["05/05/2024", None, "07/05/2024"], name="when")
>>> to_dt.transform(s)
0 NaT
1 NaT
2 NaT
Name: when, dtype: datetime64[...]
Dealing with Time zones#
During fit, parsing strings that contain fixed offsets results in datetimes
in UTC. Mixed offsets are supported and will all be converted to UTC.
>>> s = pd.Series(["2020-01-01T04:00:00+02:00", "2020-01-01T04:00:00+03:00"])
>>> to_dt.fit_transform(s)
0 2020-01-01 02:00:00+00:00
1 2020-01-01 01:00:00+00:00
dtype: datetime64[..., UTC]
>>> to_dt.format_
'%Y-%m-%dT%H:%M:%S%z'
>>> to_dt.output_time_zone_
'UTC'
Strings with no timezone indication result in naive datetimes:
>>> s = pd.Series(["2020-01-01T04:00:00", "2020-01-01T04:00:00"])
>>> to_dt.fit_transform(s)
0 2020-01-01 04:00:00
1 2020-01-01 04:00:00
dtype: datetime64[...]
>>> to_dt.output_time_zone_ is None
True
During transform, outputs are cast to the same dtype that was found
during fit. This includes the timezone, which is converted if necessary.
>>> s_paris = pd.to_datetime(
... pd.Series(["2024-05-07T14:24:49", "2024-05-06T14:24:49"])
... ).dt.tz_localize("Europe/Paris")
>>> s_paris
0 2024-05-07 14:24:49+02:00
1 2024-05-06 14:24:49+02:00
dtype: datetime64[..., Europe/Paris]
>>> to_dt = ToDatetime().fit(s_paris)
>>> to_dt.output_dtype_
datetime64[..., Europe/Paris]
Here our converter is set to output datetimes with nanosecond resolution, localized in “Europe/Paris”.
We may have a column in a different timezone:
>>> s_london = s_paris.dt.tz_convert("Europe/London")
>>> s_london
0 2024-05-07 13:24:49+01:00
1 2024-05-06 13:24:49+01:00
dtype: datetime64[..., Europe/London]
Here the timezone is “Europe/London” and the times are offset by 1 hour. During
transform datetimes will be converted to the original dtype and the
“Europe/Paris” timezone:
>>> to_dt.transform(s_london)
0 2024-05-07 14:24:49+02:00
1 2024-05-06 14:24:49+02:00
dtype: datetime64[..., Europe/Paris]
Moreover, we may have to transform a timezone-naive column whereas the
transformer was fitted on a timezone-aware column. Note that this is somewhat a
corner case unlikely to happen in practice if the inputs to fit and
transform come from the same dataframe.
In this case, we make the arbitrary choice to assume that the timezone-naive datetimes are in UTC.
>>> s_naive = s_paris.dt.tz_convert(None)
>>> to_dt.transform(s_naive)
0 2024-05-07 14:24:49+02:00
1 2024-05-06 14:24:49+02:00
dtype: datetime64[..., Europe/Paris]
Conversely, a transformer fitted on a timezone-naive column can convert timezone-aware columns. Here also, we assume the naive datetimes were in UTC.
>>> to_dt = ToDatetime().fit(s_naive)
>>> to_dt.transform(s_london)
0 2024-05-07 12:24:49
1 2024-05-06 12:24:49
dtype: datetime64[...]
Caveats when dealing with month first/day first conventions#
When parsing strings in one of the formats above, ToDatetime tries to guess
if the month comes first (USA convention) or the day (rest of the world) from
the data.
>>> s = pd.Series(["05/23/2024"])
>>> to_dt.fit_transform(s)
0 2024-05-23
dtype: datetime64[...]
>>> to_dt.format_
'%m/%d/%Y'
Here we could infer '%m/%d/%Y' because there is no 23rd month in a year.
Similarly,
>>> s = pd.Series(["23/05/2024"])
>>> to_dt.fit_transform(s)
0 2024-05-23
dtype: datetime64[...]
>>> to_dt.format_
'%d/%m/%Y'
In the case where it cannot be inferred, the USA convention is used:
>>> s = pd.Series(["03/05/2024"])
>>> to_dt.fit_transform(s)
0 2024-03-05
dtype: datetime64[...]
>>> to_dt.format_
'%m/%d/%Y'
Encoding and Feature Engineering with DatetimeEncoder#
Once datetime columns have been parsed, they can be encoded as numeric features with
the DatetimeEncoder, by extracting temporal features (year, month, day,
hour, etc.). No timezone conversion is done; the timezone
in the feature is retained. The DatetimeEncoder rejects non-datetime columns,
so it should only be applied after conversion using ToDatetime.
If the input column is timezone aware, the extracted features will be in the column’s
timezone; this is normally the case when the datetime column has been encoded with ToDatetime.
>>> import pandas as pd
>>> login = pd.to_datetime(
... pd.Series(
... ["2024-05-13T12:05:36", None, "2024-05-15T13:46:02"], name="login")
... )
>>> login
0 2024-05-13 12:05:36
1 NaT
2 2024-05-15 13:46:02
Name: login, dtype: datetime64[...]
>>> from skrub import DatetimeEncoder
>>> DatetimeEncoder().fit_transform(login)
login_year login_month login_day login_hour login_total_seconds
0 2024.0 5.0 13.0 12.0 1.715602e+09
1 NaN NaN NaN NaN NaN
2 2024.0 5.0 15.0 13.0 1.715781e+09
Additionally, the DatetimeEncoder can include the following features:
Number of seconds from epoch (
add_total_seconds,Trueby default)Day of the week (
add_weekday)Day of the year (
add_day_of_year)
Periodic encoding is supported through trigonometric (circular) and spline
encoding: set the periodic_encoding parameter to circular or spline.
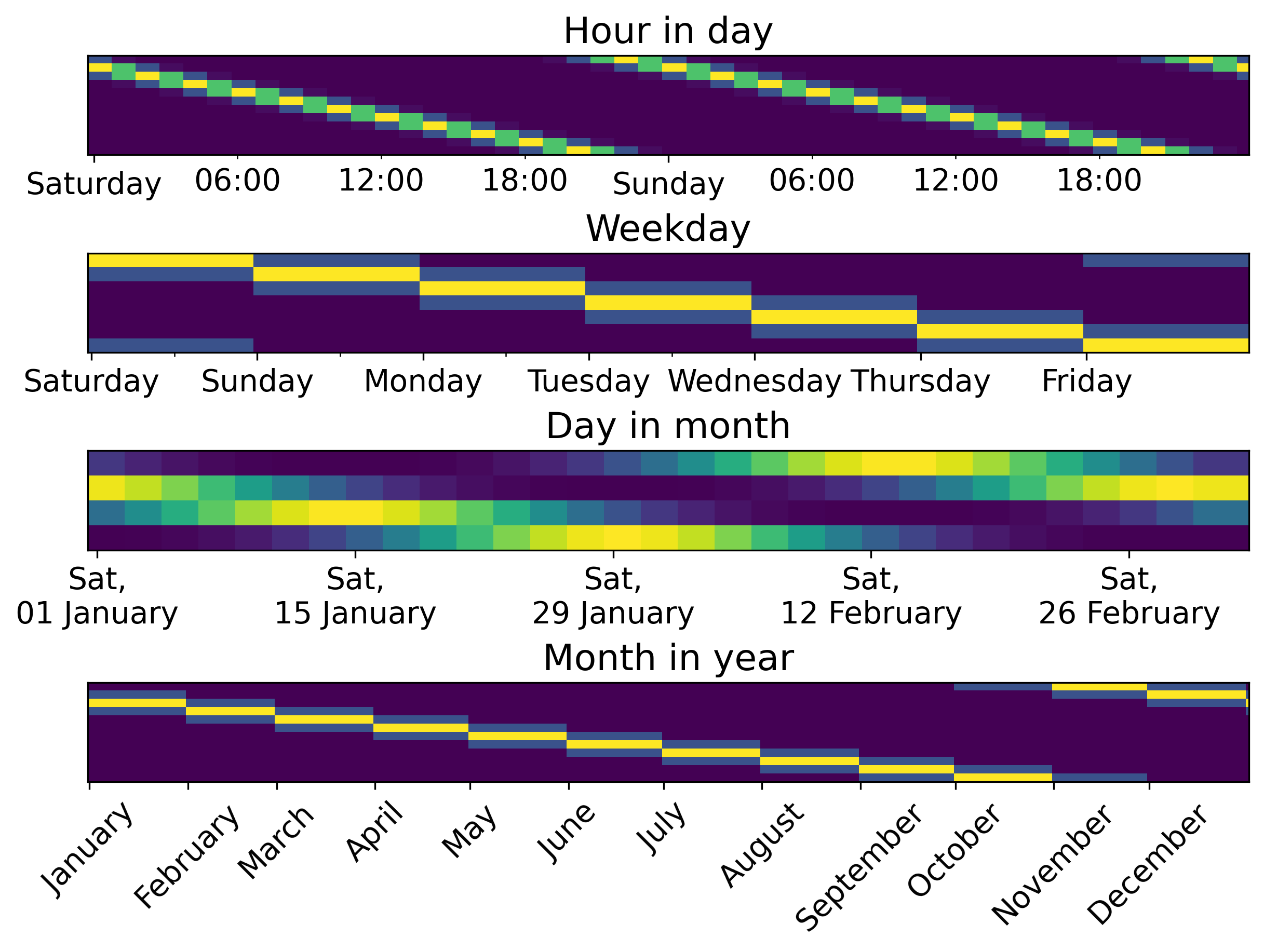
Example of periodic encoding of datetime features using circular and spline methods.#
Note that if periodic_encoding is set, the respective features are removed
to reduce redundancy:
>>> encoder = DatetimeEncoder()
>>> encoder.fit_transform(login).columns
Index(['login_year', 'login_month', 'login_day', 'login_hour',
'login_total_seconds'],
dtype=...)
>>> from sklearn.pipeline import make_pipeline
>>> encoder = make_pipeline(ToDatetime(), DatetimeEncoder(periodic_encoding="circular"))
>>> encoder.fit_transform(login).columns
Index(['login_year', 'login_total_seconds', 'login_month_circular_0',
'login_month_circular_1', 'login_day_circular_0',
'login_day_circular_1', 'login_hour_circular_0',
'login_hour_circular_1'],
dtype=...)
The DatetimeEncoder uses hardcoded values for generating periodic features.
The period of each feature is:
month: 12 (month in year)day: 30 (day in month)hour: 24 (hour in day)weekday: 7 (day in week)
Additionally, we specify the number of splines for each feature to avoid generating too many features:
month: 12day: 4hour: 12weekday: 7
All extracted features are provided as float32 columns.