
DatetimeEncoder#
- class skrub.DatetimeEncoder(resolution='hour', add_weekday=False, add_total_seconds=True, add_day_of_year=False, periodic_encoding=None)[source]#
Extract temporal features such as month, day of the week, … from a datetime column.
A note on using single column transformations
DatetimeEncoderis a type of single column transformation . Unlike most scikit-learn estimators, itsfit,transformandfit_transformmethods expect a single column (e.g. Series) not a full dataframe. To apply this transformer to one or more columns in a dataframe, use it in aApplyToColsor aTableVectorizer.To apply to all columns:
ApplyToCols(DatetimeEncoder())
To apply to selected columns:
ApplyToCols(DatetimeEncoder(), cols=['col_name_1', 'col_name_2'])
The
DatetimeEncoderconverts datetime features to numerical features that can be used by learners. It separates each datetime in its parts (year, month, day, etc.), and can add new features based on the datetime (weekday, seconds from epoch, day of year). Circular or spline-based periodic features may also be included.- Parameters:
- resolution
strorNone, default=”hour” If a string, extract up to this resolution. Must be “year”, “month”, “day”, “hour”, “minute”, “second”, “microsecond”, or “nanosecond”. For example,
resolution="day"generates the features “year”, “month”, and “day” only. If the input column contains dates with no time information, time features (“hour”, “minute”, … ) are never extracted. IfNone, the features listed above are not extracted (but day of the week and total seconds may still be extracted, see below).- add_weekday
bool, default=False Extract the day of the week as a numerical feature from 1 (Monday) to 7 (Sunday).
- add_total_seconds
bool, default=True Add the total number of seconds since the Unix epoch (00:00:00 UTC on 1 January 1970).
- add_day_of_year
bool, default=False Add the day of year (ordinal day) as an integer in the range 1 to 365 (or 366 in the case of leap years). January 1st will be day 1, December 31st will be day 365 on non-leap years.
- periodic_encoding‘circular’, ‘spline’, or
None, default=None Add periodic features with different granularities. Add periodic features using either trigonometric (
circular) orsplineencoding. IfNone, no periodic encoding is applied.
- resolution
- Attributes:
- extracted_features_
listof strings The features that are extracted, a subset of [“year”, …, “nanosecond”, “weekday”, “total_seconds”, “day_of_year”]. If
periodic_encodingis set to eithercircularorspline, the extracted periodic features will also be added. Given a feature nameddate, new features will be nameddate_month_circular_0,date_month_circular_1etc., ordate_month_spline_00,date_month_spline_01etc., accordingly.
- extracted_features_
See also
ToDatetimeConvert strings to datetimes.
Notes
All extracted features are provided as float32 columns.
No timezone conversion is performed: if the input column is timezone aware, the extracted features will be in the column’s timezone.
An input column that does not have a Date or Datetime dtype will be rejected by raising a
RejectColumnexception. SeeToDatetimefor converting strings to proper datetimes. Note: theTableVectorizeronly sends datetime columns to itsdatetime_encoder. Therefore it is always safe to use aDatetimeEncoderas theTableVectorizer’sdatetime_encoderparameter.The
DatetimeEncoderuses hardcoded values for generating periodic features. The period of each feature is:month: 12 (month in year)day: 30 (day in month)hour: 24 (hour in day)weekday: 7 (day in week)
Additionally, we specify the number of splines for each feature to avoid generating too many features:
month: 12day: 4hour: 12weekday: 7
Examples
>>> import pandas as pd >>> login = pd.to_datetime( ... pd.Series( ... ["2024-05-13T12:05:36", None, "2024-05-15T13:46:02"], name="login") ... ) >>> login 0 2024-05-13 12:05:36 1 NaT 2 2024-05-15 13:46:02 Name: login, dtype: datetime64[...] >>> from skrub import DatetimeEncoder >>> DatetimeEncoder().fit_transform(login) login_year login_month login_day login_hour login_total_seconds 0 2024.0 5.0 13.0 12.0 1.715602e+09 1 NaN NaN NaN NaN NaN 2 2024.0 5.0 15.0 13.0 1.715781e+09
We can ask for a finer resolution:
>>> DatetimeEncoder(resolution='second', add_total_seconds=False).fit_transform( ... login ... ) login_year login_month login_day login_hour login_minute login_second 0 2024.0 5.0 13.0 12.0 5.0 36.0 1 NaN NaN NaN NaN NaN NaN 2 2024.0 5.0 15.0 13.0 46.0 2.0
We can also ask for the day of the week. The week starts at 1 on Monday and ends at 7 on Sunday. This is consistent with the ISO week date system, the standard library
datetime.isoweekday()and polarsweekday, but not with pandasday_of_week, which counts days from 0.>>> login.dt.strftime('%A = %w') 0 Monday = 1 1 NaN 2 Wednesday = 3 Name: login, dtype: ... >>> login.dt.day_of_week 0 0.0 1 NaN 2 2.0 Name: login, dtype: float64 >>> DatetimeEncoder(add_weekday=True, add_total_seconds=False).fit_transform(login) login_year login_month login_day login_hour login_weekday 0 2024.0 5.0 13.0 12.0 1.0 1 NaN NaN NaN NaN NaN 2 2024.0 5.0 15.0 13.0 3.0
When a column contains only dates without time information, the time features are discarded, regardless of
resolution.>>> birthday = pd.to_datetime( ... pd.Series(['2024-04-14', '2024-05-15'], name='birthday') ... ) >>> encoder = DatetimeEncoder(resolution='second') >>> encoder.fit_transform(birthday) birthday_year birthday_month birthday_day birthday_total_seconds 0 2024.0 4.0 14.0 1.713053e+09 1 2024.0 5.0 15.0 1.715731e+09 >>> encoder.extracted_features_ ['year', 'month', 'day', 'total_seconds'] >>> encoder.all_outputs_ ['birthday_year', 'birthday_month', 'birthday_day', 'birthday_total_seconds']
(The number of seconds since Epoch can still be extracted but not “hour”, “minute”, etc.)
Non-datetime columns are rejected by raising a
RejectColumnexception.>>> s = pd.Series(['2024-04-14', '2024-05-15'], name='birthday') >>> s 0 2024-04-14 1 2024-05-15 Name: birthday, dtype: ... >>> DatetimeEncoder().fit_transform(s) Traceback (most recent call last): ... skrub.core.RejectColumn: Column 'birthday' does not have Date or Datetime dtype.
ToDatetime: can be used for converting strings to datetimes.>>> from skrub import ToDatetime >>> from sklearn.pipeline import make_pipeline >>> make_pipeline(ToDatetime(), DatetimeEncoder()).fit_transform(s) birthday_year birthday_month birthday_day birthday_total_seconds 0 2024.0 4.0 14.0 1.713053e+09 1 2024.0 5.0 15.0 1.715731e+09
Time zones
If the input column has a time zone, the extracted features are in this time zone.
>>> login = pd.to_datetime( ... pd.Series( ... ["2024-05-13T12:05:36", None, "2024-05-15T13:46:02"], name="login") ... ).dt.tz_localize('Europe/Paris') >>> encoder = DatetimeEncoder() >>> encoder.fit_transform(login)['login_hour'] 0 12.0 1 NaN 2 13.0 Name: login_hour, dtype: float32
No special care is taken to convert inputs to
transformto the same time zone as the column the encoder was fitted on. The features are always in the time zone of the input.>>> login_sp = login.dt.tz_convert('America/Sao_Paulo') >>> login_sp 0 2024-05-13 07:05:36-03:00 1 NaT 2 2024-05-15 08:46:02-03:00 Name: login, dtype: datetime64[..., America/Sao_Paulo] >>> encoder.transform(login_sp)['login_hour'] 0 7.0 1 NaN 2 8.0 Name: login_hour, dtype: float32
To ensure datetime columns are in a consistent timezones, use
ToDatetime.>>> encoder = make_pipeline(ToDatetime(), DatetimeEncoder()) >>> encoder.fit_transform(login)['login_hour'] 0 12.0 1 NaN 2 13.0 Name: login_hour, dtype: float32 >>> encoder.transform(login_sp)['login_hour'] 0 12.0 1 NaN 2 13.0 Name: login_hour, dtype: float32
Here we can see the Sao Paulo input of the encoder has been converted back to the time zone used during the fitting and that we get the same result for “hour”.
The DatetimeEncoder can also create new features based on either trigonometric functions or splines by setting
periodic_encoder="circular"orperiodic_encoder="spline"respectively. See this example in scikit-learn to know more about cyclical feature engineering.>>> encoder = make_pipeline(ToDatetime(), DatetimeEncoder(periodic_encoding="circular")) >>> encoder.fit_transform(login) login_year ... login_hour_circular_1 0 2024.0 ... -1.000000 1 NaN ... NaN 2 2024.0 ... -0.965926
Added features can be explored using
DatetimeEncoder.all_outputs_:>>> encoder[-1].all_outputs_ ['login_year', 'login_total_seconds', 'login_month_circular_0', 'login_month_circular_1', 'login_day_circular_0', 'login_day_circular_1', 'login_hour_circular_0', 'login_hour_circular_1']
Methods
fit(column[, y])Fit the transformer.
fit_transform(column[, y])Fit the encoder and transform a column.
get_feature_names_out([input_features])Get output feature names for transformation.
get_params([deep])Get parameters for this estimator.
set_output(*[, transform])Default no-op implementation for set_output.
set_params(**params)Set the parameters of this estimator.
set_transform_request(*[, column])Configure whether metadata should be requested to be passed to the
transformmethod.transform(column)Transform a column.
- fit(column, y=None, **kwargs)[source]#
Fit the transformer.
This default implementation simply calls
fit_transform()and returnsself.Subclasses should implement
fit_transformandtransform.- Parameters:
- columna pandas or polars
Series Unlike most scikit-learn transformers, single-column transformers transform a single column, not a whole dataframe.
- ycolumn or dataframe
Prediction targets.
- **kwargs
Extra named arguments are passed to
self.fit_transform().
- columna pandas or polars
- Returns:
- self
The fitted transformer.
- get_feature_names_out(input_features=None)[source]#
Get output feature names for transformation.
- Parameters:
- input_featuresarray_like of
strorNone, default=None Ignored.
- input_featuresarray_like of
- Returns:
- set_output(*, transform=None)[source]#
Default no-op implementation for set_output.
Skrub transformers already output dataframes of the correct type by default so there is usually no need for set_output to do anything.
Subclasses are of course free to redefine set_output (e.g. by inheriting from
TransformerMixinbefore SingleColumnTransformer).
- set_params(**params)[source]#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **params
dict Estimator parameters.
- **params
- Returns:
- selfestimator instance
Estimator instance.
- set_transform_request(*, column='$UNCHANGED$')[source]#
Configure whether metadata should be requested to be passed to the
transformmethod.Note that this method is only relevant when this estimator is used as a sub-estimator within a meta-estimator and metadata routing is enabled with
enable_metadata_routing=True(seesklearn.set_config()). Please check the User Guide on how the routing mechanism works.The options for each parameter are:
True: metadata is requested, and passed totransformif provided. The request is ignored if metadata is not provided.False: metadata is not requested and the meta-estimator will not pass it totransform.None: metadata is not requested, and the meta-estimator will raise an error if the user provides it.str: metadata should be passed to the meta-estimator with this given alias instead of the original name.
The default (
sklearn.utils.metadata_routing.UNCHANGED) retains the existing request. This allows you to change the request for some parameters and not others.Added in version 1.3.
Gallery examples#

SquashingScaler: Robust numerical preprocessing for neural networks

Encoding: from a dataframe to a numerical matrix for machine learning
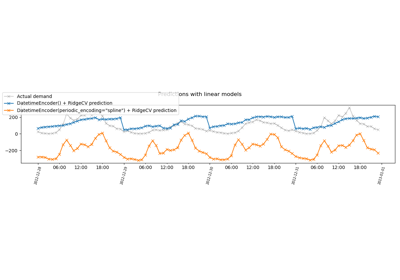
Handling datetime features with the DatetimeEncoder