
Note
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
Spatial join for flight data: Joining across multiple columns#
Joining tables may be difficult if one entry on one side does not have an exact match on the other side.
This problem becomes even more complex when multiple columns are significant for the join. For instance, this is the case for spatial joins on two columns, typically longitude and latitude.
Joiner() is a scikit-learn compatible transformer that enables
performing joins across multiple keys,
independently of the data type (numerical, string or mixed).
The following example uses US domestic flights data to illustrate how space and time information from a pool of tables are combined for machine learning.
Flight-delays data#
The goal is to predict flight delays. We have a pool of tables that we will use to improve our prediction.
The following tables are at our disposal:
The main table: flights dataset#
The flights datasets. It contains all US flights date, origin and destination airports and flight time. Here, we consider only flights from 2008.
import pandas as pd
from skrub.datasets import fetch_flight_delays
dataset = fetch_flight_delays()
seed = 1
flights = dataset.flights
# Sampling for faster computation.
flights = flights.sample(5_000, random_state=seed, ignore_index=True)
flights.head()
Let us see the arrival delay of the flights in the dataset:
import matplotlib.pyplot as plt
import seaborn as sns
sns.set_theme(style="ticks")
ax = sns.histplot(data=flights, x="ArrDelay")
ax.set_yscale("log")
plt.show()
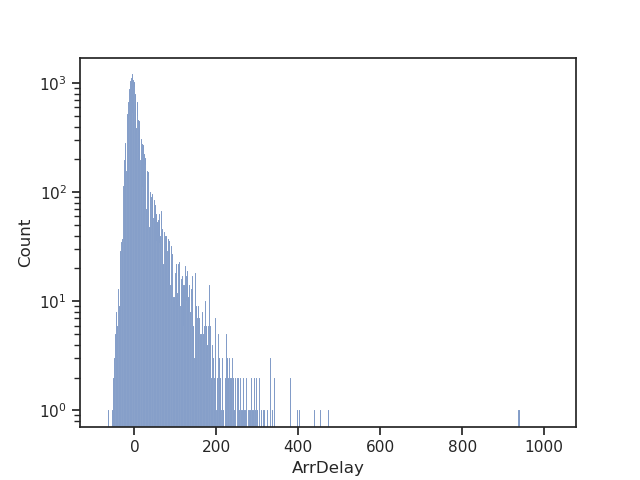
Interesting, most delays are relatively short (<100 min), but there are some very long ones.
Airport data: an auxiliary table from the same database#
The
airportsdataset, with information such as their name and location (longitude, latitude).
Weather data: auxiliary tables from external sources#
The
weathertable. Weather details by measurement station. Both tables are from the Global Historical Climatology Network. Here, we consider only weather measurements from 2008.
weather = dataset.weather
# Sampling for faster computation.
weather = weather.sample(10_000, random_state=seed, ignore_index=True)
weather.head()
The
stationsdataset. Provides location of all the weather measurement stations in the US.
Joining: feature augmentation across tables#
First we join the stations with weather on the ID (exact join):
Then we join this table with the airports so that we get all auxiliary tables into one.
from skrub import Joiner
joiner = Joiner(airports, aux_key=["lat", "long"], main_key=["LATITUDE", "LONGITUDE"])
aux_augmented = joiner.fit_transform(aux)
aux_augmented.head()
Joining airports with flights data: Let’s instantiate another multiple key joiner on the date and the airport:
joiner = Joiner(
aux_augmented,
aux_key=["YEAR/MONTH/DAY", "iata"],
main_key=["Year_Month_DayofMonth", "Origin"],
)
flights.drop(columns=["TailNum", "FlightNum"])
Training data is then passed through a Pipeline:
We will combine all the information from our pool of tables into “flights”,
our main table. - We will use this main table to model the prediction of flight delay.
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.pipeline import make_pipeline
from skrub import TableVectorizer
tv = TableVectorizer()
hgb = HistGradientBoostingClassifier()
pipeline_hgb = make_pipeline(joiner, tv, hgb)
We isolate our target variable and remove useless ID variables:
y = flights["ArrDelay"]
X = flights.drop(columns=["ArrDelay"])
We want to frame this as a classification problem: suppose that your company is obliged to reimburse the ticket price if the flight is delayed.
We have a binary classification problem: the flight was delayed (1) or not (0).
y = (y > 0).astype(int)
y.value_counts()
ArrDelay
0 2727
1 2273
Name: count, dtype: int64
The results:
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=seed)
pipeline_hgb.fit(X_train, y_train).score(X_test, y_test)
0.5616
Conclusion#
In this example, we have combined multiple tables with complex joins
on imprecise and multiple-key correspondences.
This is made easy by skrub’s Joiner() transformer.
Our final cross-validated accuracy score is 0.55.
Total running time of the script: (0 minutes 13.659 seconds)