
Note
Go to the end to download the full example code. or to run this example in your browser via JupyterLite or Binder
AggJoiner on a credit fraud dataset#
Many problems involve tables whose entities have a one-to-many relationship.
To simplify aggregate-then-join operations for machine learning, we can include
the AggJoiner in our pipeline.
In this example, we are tackling a fraudulent loan detection use case. Because fraud is rare, this dataset is extremely imbalanced, with a prevalence of around 1.4%.
The data consists of two distinct entities: e-commerce “baskets”, and “products”. Baskets can be tagged fraudulent (1) or not (0), and are essentially a list of products of variable size. Each basket is linked to at least one products, e.g. basket 1 can have product 1 and 2.
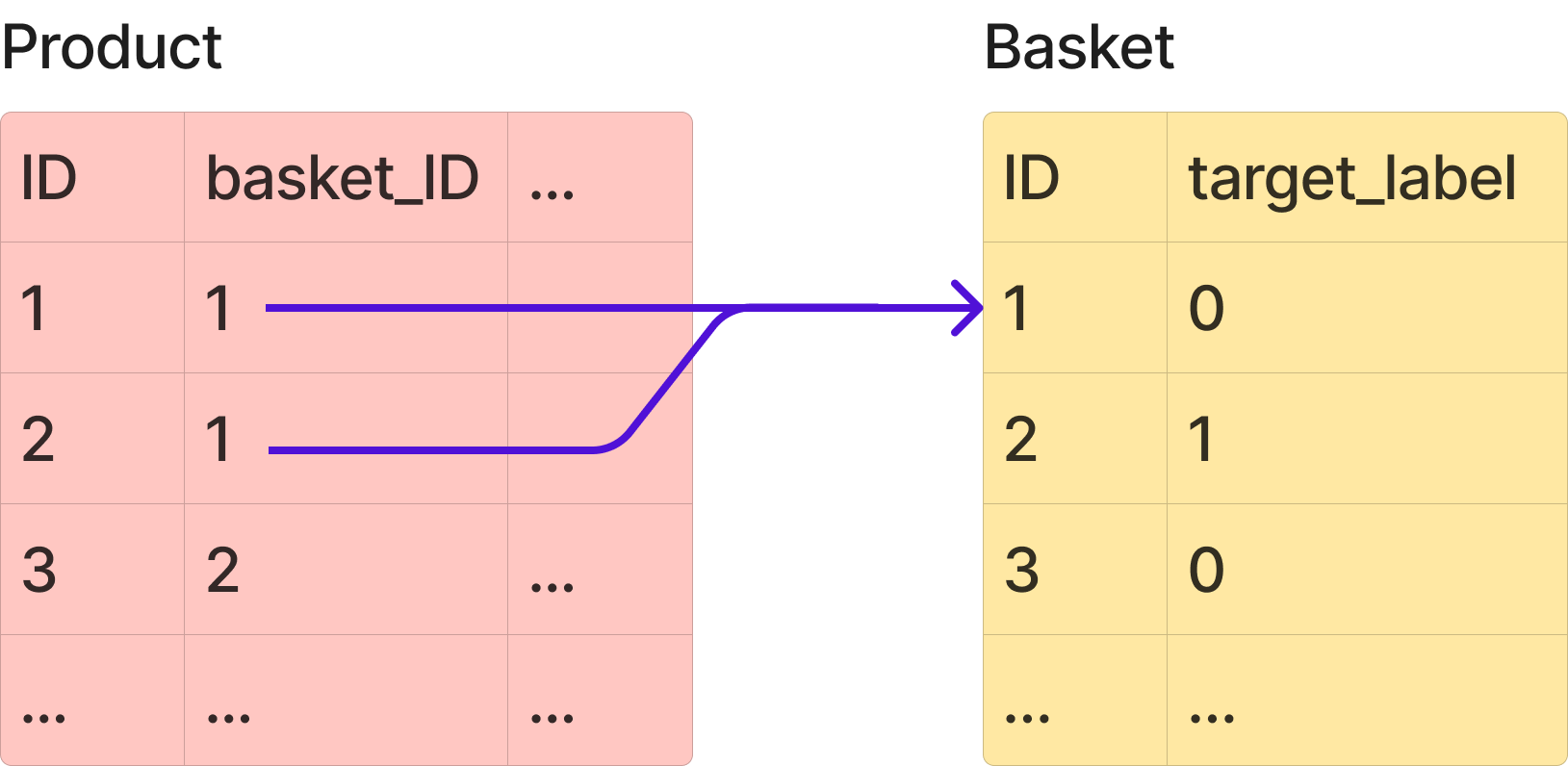
Our aim is to predict which baskets are fraudulent.
The products dataframe can be joined on the baskets dataframe using the basket_ID
column.
Each product has several attributes:
a category (marked by the column
"item"),a model (
"model"),a brand (
"make"),a merchant code (
"goods_code"),a price per unit (
"cash_price"),a quantity selected in the basket (
"Nbr_of_prod_purchas")
from skrub import TableReport
from skrub.datasets import fetch_credit_fraud
bunch = fetch_credit_fraud()
products, baskets = bunch.products, bunch.baskets
TableReport(products)
| basket_ID | item | cash_price | make | model | goods_code | Nbr_of_prod_purchas | |
|---|---|---|---|---|---|---|---|
| 1 | 51,113 | COMPUTER PERIPHERALS ACCESSORIES | 409 | APPLE | APPLE WATCH SERIES 6 GPS 44MM SPACE GREY ALUMINIUM | 239001518 | 1 |
| 9 | 41,798 | COMPUTERS | 1,187 | APPLE | 2020 APPLE MACBOOK PRO 13 TOUCH BAR M1 PROCESSOR 8 | 239246780 | 1 |
| 11 | 39,361 | COMPUTERS | 898 | APPLE | 2020 APPLE MACBOOK AIR 13 3 RETINA DISPLAY M1 PROC | 239246776 | 1 |
| 15 | 38,615 | COMPUTER PERIPHERALS ACCESSORIES | 379 | APPLE | APPLE WATCH SERIES 6 GPS 40MM BLUE ALUMINIUM CASE | 239001540 | 1 |
| 16 | 70,262 | COMPUTERS | 1,899 | APPLE | 2021 APPLE MACBOOK PRO 14 M1 PRO PROCESSOR 16GB RA | 240575990 | 1 |
| 163,352 | 42,613 | BEDROOM FURNITURE | 259 | SILENTNIGHT | SILENTNIGHT SLEEP GENIUS FULL HEIGHT HEADBOARD DOU | 236938439 | 1 |
| 163,353 | 42,613 | OUTDOOR FURNITURE | 949 | LG OUTDOOR | LG OUTDOOR BERGEN 2-SEAT GARDEN SIDE TABLE RECLINI | 239742814 | 1 |
| 163,354 | 43,567 | COMPUTERS | 1,099 | APPLE | 2021 APPLE IPAD PRO 12 9 M1 PROCESSOR IOS WI-FI 25 | 240040978 | 1 |
| 163,355 | 43,567 | COMPUTERS | 2,099 | APPLE | 2020 APPLE IMAC 27 ALL-IN-ONE INTEL CORE I7 8GB RA | 238923518 | 1 |
| 163,356 | 68,268 | TELEVISIONS HOME CINEMA | 799 | LG | LG OLED48A16LA 2021 OLED HDR 4K ULTRA HD SMART TV | 239866717 | 1 |
basket_ID
Int64DType- Null values
- 0 (0.0%)
- Unique values
-
61,241 (56.0%)
This column has a high cardinality (> 40).
- Mean ± Std
- 3.59e+04 ± 2.24e+04
- Median ± IQR
- 35,203 ± 39,444
- Min | Max
- 0 | 76,543
item
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
166 (0.2%)
This column has a high cardinality (> 40).
Most frequent values
cash_price
Int64DType- Null values
- 0 (0.0%)
- Unique values
-
1,280 (1.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- 672. ± 714.
- Median ± IQR
- 499 ± 1,049
- Min | Max
- 0 | 18,349
make
ObjectDType- Null values
- 1,273 (1.2%)
- Unique values
-
690 (0.6%)
This column has a high cardinality (> 40).
Most frequent values
model
ObjectDType- Null values
- 1,273 (1.2%)
- Unique values
-
6,477 (5.9%)
This column has a high cardinality (> 40).
Most frequent values
goods_code
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
10,738 (9.8%)
This column has a high cardinality (> 40).
Most frequent values
Nbr_of_prod_purchas
Int64DType- Null values
- 0 (0.0%)
- Unique values
- 19 (< 0.1%)
- Mean ± Std
- 1.05 ± 0.426
- Median ± IQR
- 1 ± 0
- Min | Max
- 1 | 40
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
| Column | Column name | dtype | Is sorted | Null values | Unique values | Mean | Std | Min | Median | Max |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | basket_ID | Int64DType | False | 0 (0.0%) | 61241 (56.0%) | 3.59e+04 | 2.24e+04 | 0 | 35,203 | 76,543 |
| 1 | item | ObjectDType | False | 0 (0.0%) | 166 (0.2%) | |||||
| 2 | cash_price | Int64DType | False | 0 (0.0%) | 1280 (1.2%) | 672. | 714. | 0 | 499 | 18,349 |
| 3 | make | ObjectDType | False | 1273 (1.2%) | 690 (0.6%) | |||||
| 4 | model | ObjectDType | False | 1273 (1.2%) | 6477 (5.9%) | |||||
| 5 | goods_code | ObjectDType | False | 0 (0.0%) | 10738 (9.8%) | |||||
| 6 | Nbr_of_prod_purchas | Int64DType | False | 0 (0.0%) | 19 (< 0.1%) | 1.05 | 0.426 | 1 | 1 | 40 |
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
basket_ID
Int64DType- Null values
- 0 (0.0%)
- Unique values
-
61,241 (56.0%)
This column has a high cardinality (> 40).
- Mean ± Std
- 3.59e+04 ± 2.24e+04
- Median ± IQR
- 35,203 ± 39,444
- Min | Max
- 0 | 76,543
item
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
166 (0.2%)
This column has a high cardinality (> 40).
Most frequent values
cash_price
Int64DType- Null values
- 0 (0.0%)
- Unique values
-
1,280 (1.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- 672. ± 714.
- Median ± IQR
- 499 ± 1,049
- Min | Max
- 0 | 18,349
make
ObjectDType- Null values
- 1,273 (1.2%)
- Unique values
-
690 (0.6%)
This column has a high cardinality (> 40).
Most frequent values
model
ObjectDType- Null values
- 1,273 (1.2%)
- Unique values
-
6,477 (5.9%)
This column has a high cardinality (> 40).
Most frequent values
goods_code
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
10,738 (9.8%)
This column has a high cardinality (> 40).
Most frequent values
Nbr_of_prod_purchas
Int64DType- Null values
- 0 (0.0%)
- Unique values
- 19 (< 0.1%)
- Mean ± Std
- 1.05 ± 0.426
- Median ± IQR
- 1 ± 0
- Min | Max
- 1 | 40
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
| Column 1 | Column 2 | Cramér's V | Pearson's Correlation |
|---|---|---|---|
| model | goods_code | 0.612 | |
| item | model | 0.480 | |
| item | make | 0.465 | |
| item | goods_code | 0.436 | |
| make | model | 0.312 | |
| make | goods_code | 0.256 | |
| basket_ID | item | 0.207 | |
| basket_ID | model | 0.205 | |
| cash_price | make | 0.139 | |
| basket_ID | make | 0.137 | |
| item | cash_price | 0.133 | |
| make | Nbr_of_prod_purchas | 0.123 | |
| basket_ID | goods_code | 0.108 | |
| item | Nbr_of_prod_purchas | 0.0977 | |
| cash_price | model | 0.0917 | |
| basket_ID | cash_price | 0.0729 | 0.120 |
| cash_price | goods_code | 0.0685 | |
| goods_code | Nbr_of_prod_purchas | 0.0460 | |
| basket_ID | Nbr_of_prod_purchas | 0.0455 | -0.0328 |
| model | Nbr_of_prod_purchas | 0.0378 |
Please enable javascript
The skrub table reports need javascript to display correctly. If you are displaying a report in a Jupyter notebook and you see this message, you may need to re-execute the cell or to trust the notebook (button on the top right or "File > Trust notebook").
| ID | fraud_flag | |
|---|---|---|
| 1 | 51,113 | 0 |
| 7 | 41,798 | 0 |
| 9 | 39,361 | 0 |
| 13 | 38,615 | 0 |
| 14 | 70,262 | 0 |
| 92,785 | 21,243 | 0 |
| 92,786 | 45,891 | 0 |
| 92,787 | 42,613 | 0 |
| 92,788 | 43,567 | 0 |
| 92,789 | 68,268 | 0 |
ID
Int64DType- Null values
- 0 (0.0%)
- Unique values
-
61,241 (100.0%)
This column has a high cardinality (> 40).
- Mean ± Std
- 3.82e+04 ± 2.21e+04
- Median ± IQR
- 38,158 ± 38,196
- Min | Max
- 0 | 76,543
fraud_flag
Int64DType- Null values
- 0 (0.0%)
- Unique values
- 2 (< 0.1%)
- Mean ± Std
- 0.0130 ± 0.113
- Median ± IQR
- 0 ± 0
- Min | Max
- 0 | 1
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
| Column | Column name | dtype | Is sorted | Null values | Unique values | Mean | Std | Min | Median | Max |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ID | Int64DType | False | 0 (0.0%) | 61241 (100.0%) | 3.82e+04 | 2.21e+04 | 0 | 38,158 | 76,543 |
| 1 | fraud_flag | Int64DType | False | 0 (0.0%) | 2 (< 0.1%) | 0.0130 | 0.113 | 0 | 0 | 1 |
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
ID
Int64DType- Null values
- 0 (0.0%)
- Unique values
-
61,241 (100.0%)
This column has a high cardinality (> 40).
- Mean ± Std
- 3.82e+04 ± 2.21e+04
- Median ± IQR
- 38,158 ± 38,196
- Min | Max
- 0 | 76,543
fraud_flag
Int64DType- Null values
- 0 (0.0%)
- Unique values
- 2 (< 0.1%)
- Mean ± Std
- 0.0130 ± 0.113
- Median ± IQR
- 0 ± 0
- Min | Max
- 0 | 1
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
| Column 1 | Column 2 | Cramér's V | Pearson's Correlation |
|---|---|---|---|
| ID | fraud_flag | 0.0709 | 0.0161 |
Please enable javascript
The skrub table reports need javascript to display correctly. If you are displaying a report in a Jupyter notebook and you see this message, you may need to re-execute the cell or to trust the notebook (button on the top right or "File > Trust notebook").
Naive aggregation#
Let’s explore a naive solution first.
Note
Click here to skip this section and see the AggJoiner in action!
The first idea that comes to mind to merge these two tables is to aggregate the products attributes into lists, using their basket IDs.
products_grouped = products.groupby("basket_ID").agg(list)
TableReport(products_grouped)
Then, we can expand all lists into columns, as if we were “flattening” the dataframe.
We end up with a products dataframe ready to be joined on the baskets dataframe, using
"basket_ID" as the join key.
import pandas as pd
products_flatten = []
for col in products_grouped.columns:
cols = [f"{col}{idx}" for idx in range(24)]
products_flatten.append(pd.DataFrame(products_grouped[col].to_list(), columns=cols))
products_flatten = pd.concat(products_flatten, axis=1)
products_flatten.insert(0, "basket_ID", products_grouped.index)
TableReport(products_flatten)
| basket_ID | item0 | item1 | item2 | item3 | item4 | item5 | item6 | item7 | item8 | item9 | item10 | item11 | item12 | item13 | item14 | item15 | item16 | item17 | item18 | item19 | item20 | item21 | item22 | item23 | cash_price0 | cash_price1 | cash_price2 | cash_price3 | cash_price4 | cash_price5 | cash_price6 | cash_price7 | cash_price8 | cash_price9 | cash_price10 | cash_price11 | cash_price12 | cash_price13 | cash_price14 | cash_price15 | cash_price16 | cash_price17 | cash_price18 | cash_price19 | cash_price20 | cash_price21 | cash_price22 | cash_price23 | make0 | make1 | make2 | make3 | make4 | make5 | make6 | make7 | make8 | make9 | make10 | make11 | make12 | make13 | make14 | make15 | make16 | make17 | make18 | make19 | make20 | make21 | make22 | make23 | model0 | model1 | model2 | model3 | model4 | model5 | model6 | model7 | model8 | model9 | model10 | model11 | model12 | model13 | model14 | model15 | model16 | model17 | model18 | model19 | model20 | model21 | model22 | model23 | goods_code0 | goods_code1 | goods_code2 | goods_code3 | goods_code4 | goods_code5 | goods_code6 | goods_code7 | goods_code8 | goods_code9 | goods_code10 | goods_code11 | goods_code12 | goods_code13 | goods_code14 | goods_code15 | goods_code16 | goods_code17 | goods_code18 | goods_code19 | goods_code20 | goods_code21 | goods_code22 | goods_code23 | Nbr_of_prod_purchas0 | Nbr_of_prod_purchas1 | Nbr_of_prod_purchas2 | Nbr_of_prod_purchas3 | Nbr_of_prod_purchas4 | Nbr_of_prod_purchas5 | Nbr_of_prod_purchas6 | Nbr_of_prod_purchas7 | Nbr_of_prod_purchas8 | Nbr_of_prod_purchas9 | Nbr_of_prod_purchas10 | Nbr_of_prod_purchas11 | Nbr_of_prod_purchas12 | Nbr_of_prod_purchas13 | Nbr_of_prod_purchas14 | Nbr_of_prod_purchas15 | Nbr_of_prod_purchas16 | Nbr_of_prod_purchas17 | Nbr_of_prod_purchas18 | Nbr_of_prod_purchas19 | Nbr_of_prod_purchas20 | Nbr_of_prod_purchas21 | Nbr_of_prod_purchas22 | Nbr_of_prod_purchas23 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0 | COMPUTERS | WARRANTY | FULFILMENT CHARGE | 1,249 | 35.0 | 11.0 | APPLE | RETAILER | RETAILER | 2021 APPLE IMAC 24 ALL-IN-ONE M1 PROCESSOR 8GB RAM | RETAILER | RETAILER | 240040969 | 236604727 | FULFILMENT | 1 | 1.00 | 1.00 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 1 | 1 | OUTDOOR ACCESSORIES | OUTDOOR FURNITURE | 679 | 369. | KETTLER | RETAILER | RETAILER | RETAILER | 237874616 | 238222170 | 1 | 1.00 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 2 | 2 | OUTDOOR FURNITURE | OUTDOOR FURNITURE | 1,879 | 110. | KETTLER | KETTLER | RETAILER | RETAILER | 239482916 | 235452317 | 1 | 1.00 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 3 | 4 | TELEPHONES, FAX MACHINES & TWO-WAY RADIOS | FULFILMENT CHARGE | 999 | 0.00 | APPLE | RETAILER | APPLE IPHONE 12 PRO | RETAILER | 239091969 | FULFILMENT | 1 | 1.00 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 4 | 5 | LIVING & DINING FURNITURE | 749 | RETAILER | RETAILER | 238000174 | 1 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 61,236 | 76,538 | HOT DRINK PREPARATION | BARWARE | KITCHEN SCALES MEASURES | KITCHEN SCALES MEASURES | WINDOW DRESSING | LIVING DINING FURNITURE | SERVICE | LIVING DINING FURNITURE | 6 | 5.00 | 2.00 | 1.00 | 120. | 1.55e+03 | 0.00 | 1.35e+03 | RETAILER | RETAILER | ANYDAY RETAILER | ANYDAY RETAILER | RETAILER | RETAILER | RETAILER | RETAILER | RETAILER TEA STRAINER WITH STAND | RETAILER DOUBLE JIGGER | ANYDAY RETAILER PLASTIC MEASURING JUG 1 | ANYDAY RETAILER PLASTIC MEASURING JUG 5 | RETAILER RONA PAIR LINED EYELET CURTAIN | RETAILER BARBICAN LARGE 3 SEATER SOFA L | RETAILER | RETAILER BARBICAN MEDIUM 2 SEATER SOFA | 231251059 | 231034699 | 236902782 | 236902832 | 237968549 | 237013495 | DMS4462 | 237013514 | 1 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 61,237 | 76,539 | AUDIO ACCESSORIES | WARRANTY | HEALTH BEAUTY ELECTRICAL | WARRANTY | 140 | 20.0 | 357. | 15.0 | APPLE | RETAILER | DYSON | RETAILER | 2021 APPLE AIRPODS WITH MAGSAFE CHARGING CASE 3RD | RETAILER | DYSON CORRALE CORD-FREE HAIR STRAIGHTENERS | RETAILER | 240575988 | 236604738 | 238602413 | 237371145 | 1 | 1.00 | 1.00 | 1.00 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 61,238 | 76,540 | COMPUTER PERIPHERALS ACCESSORIES | 399 | APPLE | APPLE WATCH NIKE SERIES 7 GPS 45MM MIDNIGHT ALUMIN | 240382077 | 1 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 61,239 | 76,541 | BEDROOM FURNITURE | SERVICE | BEDROOM FURNITURE | BEDROOM FURNITURE | SERVICE | SERVICE | BED LINEN | BEDROOM FURNITURE | 1,519 | 30.0 | 279. | 339. | 30.0 | 0.00 | 26.0 | 749. | RETAILER | RETAILER | RETAILER | SILENTNIGHT | RETAILER | RETAILER | RETAILER | RETAILER | RETAILER LUXURY NATURAL COLLECTION BRIT | RETAILER | RETAILER CLASSIC ECO 800 POCKET SPRING | SILENTNIGHT NON SPRUNG 2 DRAWER DIVAN STORAGE BED | RETAILER | RETAILER | RETAILER NATURAL COTTON QUILTED MATTRES | RETAILER ROUEN OTTOMAN STORAGE UPHOLSTE | 240361566 | DMS22 | 240108867 | 236938413 | DMS22 | DMS4463 | 231083318 | 238088761 | 1 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | 1.00 | ||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
| 61,240 | 76,543 | COMPUTERS | FULFILMENT CHARGE | 1,649 | 7.00 | APPLE | RETAILER | 2021 APPLE IMAC 24 ALL-IN-ONE M1 PROCESSOR 8GB RAM | RETAILER | 240040968 | FULFILMENT | 1 | 1.00 |
basket_ID
Int64DType- Null values
- 0 (0.0%)
- Unique values
-
61,241 (100.0%)
This column has a high cardinality (> 40).
- Mean ± Std
- 3.82e+04 ± 2.21e+04
- Median ± IQR
- 38,158 ± 38,196
- Min | Max
- 0 | 76,543
item0
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
133 (0.2%)
This column has a high cardinality (> 40).
item1
ObjectDType- Null values
- 30,267 (49.4%)
- Unique values
-
130 (0.2%)
This column has a high cardinality (> 40).
item2
ObjectDType- Null values
- 52,467 (85.7%)
- Unique values
-
121 (0.2%)
This column has a high cardinality (> 40).
item3
ObjectDType- Null values
- 58,223 (95.1%)
- Unique values
-
119 (0.2%)
This column has a high cardinality (> 40).
item4
ObjectDType- Null values
- 59,813 (97.7%)
- Unique values
-
98 (0.2%)
This column has a high cardinality (> 40).
item5
ObjectDType- Null values
- 60,366 (98.6%)
- Unique values
-
91 (0.1%)
This column has a high cardinality (> 40).
item6
ObjectDType- Null values
- 60,632 (99.0%)
- Unique values
-
81 (0.1%)
This column has a high cardinality (> 40).
item7
ObjectDType- Null values
- 60,778 (99.2%)
- Unique values
-
76 (0.1%)
This column has a high cardinality (> 40).
item8
ObjectDType- Null values
- 60,874 (99.4%)
- Unique values
-
71 (0.1%)
This column has a high cardinality (> 40).
item9
ObjectDType- Null values
- 60,939 (99.5%)
- Unique values
-
58 (< 0.1%)
This column has a high cardinality (> 40).
item10
ObjectDType- Null values
- 60,995 (99.6%)
- Unique values
-
61 (< 0.1%)
This column has a high cardinality (> 40).
item11
ObjectDType- Null values
- 61,034 (99.7%)
- Unique values
-
49 (< 0.1%)
This column has a high cardinality (> 40).
item12
ObjectDType- Null values
- 61,074 (99.7%)
- Unique values
-
47 (< 0.1%)
This column has a high cardinality (> 40).
item13
ObjectDType- Null values
- 61,105 (99.8%)
- Unique values
-
47 (< 0.1%)
This column has a high cardinality (> 40).
item14
ObjectDType- Null values
- 61,123 (99.8%)
- Unique values
-
44 (< 0.1%)
This column has a high cardinality (> 40).
item15
ObjectDType- Null values
- 61,143 (99.8%)
- Unique values
- 36 (< 0.1%)
item16
ObjectDType- Null values
- 61,160 (99.9%)
- Unique values
- 35 (< 0.1%)
item17
ObjectDType- Null values
- 61,174 (99.9%)
- Unique values
- 29 (< 0.1%)
item18
ObjectDType- Null values
- 61,187 (99.9%)
- Unique values
- 24 (< 0.1%)
item19
ObjectDType- Null values
- 61,194 (99.9%)
- Unique values
- 20 (< 0.1%)
item20
ObjectDType- Null values
- 61,203 (99.9%)
- Unique values
- 22 (< 0.1%)
item21
ObjectDType- Null values
- 61,210 (99.9%)
- Unique values
- 15 (< 0.1%)
item22
ObjectDType- Null values
- 61,219 (100.0%)
- Unique values
- 15 (< 0.1%)
item23
ObjectDType- Null values
- 61,224 (100.0%)
- Unique values
- 11 (< 0.1%)
cash_price0
Int64DType- Null values
- 0 (0.0%)
- Unique values
-
1,102 (1.8%)
This column has a high cardinality (> 40).
- Mean ± Std
- 1.06e+03 ± 679.
- Median ± IQR
- 949 ± 675
- Min | Max
- 2 | 18,349
cash_price1
Float64DType- Null values
- 30,267 (49.4%)
- Unique values
-
689 (1.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- 180. ± 379.
- Median ± IQR
- 30.0 ± 118.
- Min | Max
- 0.00 | 6.50e+03
cash_price2
Float64DType- Null values
- 52,467 (85.7%)
- Unique values
-
511 (0.8%)
This column has a high cardinality (> 40).
- Mean ± Std
- 184. ± 369.
- Median ± IQR
- 30.0 ± 167.
- Min | Max
- 0.00 | 6.00e+03
cash_price3
Float64DType- Null values
- 58,223 (95.1%)
- Unique values
-
372 (0.6%)
This column has a high cardinality (> 40).
- Mean ± Std
- 161. ± 298.
- Median ± IQR
- 40.0 ± 161.
- Min | Max
- 0.00 | 2.85e+03
cash_price4
Float64DType- Null values
- 59,813 (97.7%)
- Unique values
-
283 (0.5%)
This column has a high cardinality (> 40).
- Mean ± Std
- 187. ± 355.
- Median ± IQR
- 52.0 ± 185.
- Min | Max
- 0.00 | 3.60e+03
cash_price5
Float64DType- Null values
- 60,366 (98.6%)
- Unique values
-
216 (0.4%)
This column has a high cardinality (> 40).
- Mean ± Std
- 161. ± 297.
- Median ± IQR
- 50.0 ± 166.
- Min | Max
- 0.00 | 3.00e+03
cash_price6
Float64DType- Null values
- 60,632 (99.0%)
- Unique values
-
173 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- 131. ± 268.
- Median ± IQR
- 50.0 ± 115.
- Min | Max
- 0.00 | 4.20e+03
cash_price7
Float64DType- Null values
- 60,778 (99.2%)
- Unique values
-
142 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- 127. ± 261.
- Median ± IQR
- 45.0 ± 100.
- Min | Max
- 0.00 | 3.00e+03
cash_price8
Float64DType- Null values
- 60,874 (99.4%)
- Unique values
-
138 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- 128. ± 274.
- Median ± IQR
- 44.0 ± 107.
- Min | Max
- 0.00 | 2.40e+03
cash_price9
Float64DType- Null values
- 60,939 (99.5%)
- Unique values
-
104 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- 93.5 ± 178.
- Median ± IQR
- 35.0 ± 72.0
- Min | Max
- 0.00 | 1.40e+03
cash_price10
Float64DType- Null values
- 60,995 (99.6%)
- Unique values
-
97 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- 101. ± 205.
- Median ± IQR
- 30.0 ± 80.0
- Min | Max
- 0.00 | 1.90e+03
cash_price11
Float64DType- Null values
- 61,034 (99.7%)
- Unique values
-
96 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- 107. ± 249.
- Median ± IQR
- 30.0 ± 67.0
- Min | Max
- 0.00 | 2.16e+03
cash_price12
Float64DType- Null values
- 61,074 (99.7%)
- Unique values
-
77 (0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- 73.3 ± 114.
- Median ± IQR
- 25.0 ± 78.0
- Min | Max
- 0.00 | 799.
cash_price13
Float64DType- Null values
- 61,105 (99.8%)
- Unique values
-
76 (0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- 93.8 ± 168.
- Median ± IQR
- 39.0 ± 85.0
- Min | Max
- 0.00 | 1.30e+03
cash_price14
Float64DType- Null values
- 61,123 (99.8%)
- Unique values
-
57 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- 67.3 ± 101.
- Median ± IQR
- 30.0 ± 58.0
- Min | Max
- 0.00 | 599.
cash_price15
Float64DType- Null values
- 61,143 (99.8%)
- Unique values
-
54 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- 88.3 ± 187.
- Median ± IQR
- 34.0 ± 72.0
- Min | Max
- 0.00 | 1.50e+03
cash_price16
Float64DType- Null values
- 61,160 (99.9%)
- Unique values
-
54 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- 110. ± 213.
- Median ± IQR
- 40.0 ± 93.0
- Min | Max
- 0.00 | 1.55e+03
cash_price17
Float64DType- Null values
- 61,174 (99.9%)
- Unique values
-
48 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- 99.6 ± 154.
- Median ± IQR
- 32.0 ± 116.
- Min | Max
- 0.00 | 799.
cash_price18
Float64DType- Null values
- 61,187 (99.9%)
- Unique values
-
42 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- 84.3 ± 152.
- Median ± IQR
- 35.0 ± 75.0
- Min | Max
- 0.00 | 999.
cash_price19
Float64DType- Null values
- 61,194 (99.9%)
- Unique values
- 37 (< 0.1%)
- Mean ± Std
- 98.2 ± 298.
- Median ± IQR
- 30.0 ± 42.0
- Min | Max
- 0.00 | 2.01e+03
cash_price20
Float64DType- Null values
- 61,203 (99.9%)
- Unique values
- 26 (< 0.1%)
- Mean ± Std
- 53.8 ± 88.1
- Median ± IQR
- 18.0 ± 42.0
- Min | Max
- 4.00 | 419.
cash_price21
Float64DType- Null values
- 61,210 (99.9%)
- Unique values
- 25 (< 0.1%)
- Mean ± Std
- 129. ± 378.
- Median ± IQR
- 25.0 ± 57.0
- Min | Max
- 0.00 | 2.09e+03
cash_price22
Float64DType- Null values
- 61,219 (100.0%)
- Unique values
- 21 (< 0.1%)
- Mean ± Std
- 129. ± 213.
- Median ± IQR
- 25.0 ± 93.0
- Min | Max
- 0.00 | 720.
cash_price23
Float64DType- Null values
- 61,224 (100.0%)
- Unique values
- 15 (< 0.1%)
- Mean ± Std
- 136. ± 260.
- Median ± IQR
- 15.0 ± 112.
- Min | Max
- 4.00 | 898.
make0
ObjectDType- Null values
- 685 (1.1%)
- Unique values
-
346 (0.6%)
This column has a high cardinality (> 40).
make1
ObjectDType- Null values
- 30,594 (50.0%)
- Unique values
-
311 (0.5%)
This column has a high cardinality (> 40).
make2
ObjectDType- Null values
- 52,577 (85.9%)
- Unique values
-
289 (0.5%)
This column has a high cardinality (> 40).
make3
ObjectDType- Null values
- 58,257 (95.1%)
- Unique values
-
243 (0.4%)
This column has a high cardinality (> 40).
make4
ObjectDType- Null values
- 59,832 (97.7%)
- Unique values
-
202 (0.3%)
This column has a high cardinality (> 40).
make5
ObjectDType- Null values
- 60,379 (98.6%)
- Unique values
-
149 (0.2%)
This column has a high cardinality (> 40).
make6
ObjectDType- Null values
- 60,642 (99.0%)
- Unique values
-
131 (0.2%)
This column has a high cardinality (> 40).
make7
ObjectDType- Null values
- 60,788 (99.3%)
- Unique values
-
122 (0.2%)
This column has a high cardinality (> 40).
make8
ObjectDType- Null values
- 60,884 (99.4%)
- Unique values
-
102 (0.2%)
This column has a high cardinality (> 40).
make9
ObjectDType- Null values
- 60,949 (99.5%)
- Unique values
-
85 (0.1%)
This column has a high cardinality (> 40).
make10
ObjectDType- Null values
- 61,003 (99.6%)
- Unique values
-
79 (0.1%)
This column has a high cardinality (> 40).
make11
ObjectDType- Null values
- 61,042 (99.7%)
- Unique values
-
67 (0.1%)
This column has a high cardinality (> 40).
make12
ObjectDType- Null values
- 61,081 (99.7%)
- Unique values
-
52 (< 0.1%)
This column has a high cardinality (> 40).
make13
ObjectDType- Null values
- 61,110 (99.8%)
- Unique values
-
53 (< 0.1%)
This column has a high cardinality (> 40).
make14
ObjectDType- Null values
- 61,128 (99.8%)
- Unique values
-
46 (< 0.1%)
This column has a high cardinality (> 40).
make15
ObjectDType- Null values
- 61,146 (99.8%)
- Unique values
- 35 (< 0.1%)
make16
ObjectDType- Null values
- 61,163 (99.9%)
- Unique values
- 31 (< 0.1%)
make17
ObjectDType- Null values
- 61,175 (99.9%)
- Unique values
- 22 (< 0.1%)
make18
ObjectDType- Null values
- 61,188 (99.9%)
- Unique values
- 25 (< 0.1%)
make19
ObjectDType- Null values
- 61,195 (99.9%)
- Unique values
- 20 (< 0.1%)
make20
ObjectDType- Null values
- 61,204 (99.9%)
- Unique values
- 17 (< 0.1%)
make21
ObjectDType- Null values
- 61,211 (100.0%)
- Unique values
- 12 (< 0.1%)
make22
ObjectDType- Null values
- 61,220 (100.0%)
- Unique values
- 12 (< 0.1%)
make23
ObjectDType- Null values
- 61,224 (100.0%)
- Unique values
- 9 (< 0.1%)
model0
ObjectDType- Null values
- 685 (1.1%)
- Unique values
-
2,624 (4.3%)
This column has a high cardinality (> 40).
model1
ObjectDType- Null values
- 30,594 (50.0%)
- Unique values
-
2,101 (3.4%)
This column has a high cardinality (> 40).
model2
ObjectDType- Null values
- 52,577 (85.9%)
- Unique values
-
1,507 (2.5%)
This column has a high cardinality (> 40).
model3
ObjectDType- Null values
- 58,257 (95.1%)
- Unique values
-
983 (1.6%)
This column has a high cardinality (> 40).
model4
ObjectDType- Null values
- 59,832 (97.7%)
- Unique values
-
658 (1.1%)
This column has a high cardinality (> 40).
model5
ObjectDType- Null values
- 60,379 (98.6%)
- Unique values
-
437 (0.7%)
This column has a high cardinality (> 40).
model6
ObjectDType- Null values
- 60,642 (99.0%)
- Unique values
-
333 (0.5%)
This column has a high cardinality (> 40).
model7
ObjectDType- Null values
- 60,788 (99.3%)
- Unique values
-
263 (0.4%)
This column has a high cardinality (> 40).
model8
ObjectDType- Null values
- 60,884 (99.4%)
- Unique values
-
212 (0.3%)
This column has a high cardinality (> 40).
model9
ObjectDType- Null values
- 60,949 (99.5%)
- Unique values
-
184 (0.3%)
This column has a high cardinality (> 40).
model10
ObjectDType- Null values
- 61,003 (99.6%)
- Unique values
-
147 (0.2%)
This column has a high cardinality (> 40).
model11
ObjectDType- Null values
- 61,042 (99.7%)
- Unique values
-
122 (0.2%)
This column has a high cardinality (> 40).
model12
ObjectDType- Null values
- 61,081 (99.7%)
- Unique values
-
99 (0.2%)
This column has a high cardinality (> 40).
model13
ObjectDType- Null values
- 61,110 (99.8%)
- Unique values
-
81 (0.1%)
This column has a high cardinality (> 40).
model14
ObjectDType- Null values
- 61,128 (99.8%)
- Unique values
-
73 (0.1%)
This column has a high cardinality (> 40).
model15
ObjectDType- Null values
- 61,146 (99.8%)
- Unique values
-
60 (< 0.1%)
This column has a high cardinality (> 40).
model16
ObjectDType- Null values
- 61,163 (99.9%)
- Unique values
-
53 (< 0.1%)
This column has a high cardinality (> 40).
model17
ObjectDType- Null values
- 61,175 (99.9%)
- Unique values
-
41 (< 0.1%)
This column has a high cardinality (> 40).
model18
ObjectDType- Null values
- 61,188 (99.9%)
- Unique values
- 36 (< 0.1%)
model19
ObjectDType- Null values
- 61,195 (99.9%)
- Unique values
- 33 (< 0.1%)
model20
ObjectDType- Null values
- 61,204 (99.9%)
- Unique values
- 25 (< 0.1%)
model21
ObjectDType- Null values
- 61,211 (100.0%)
- Unique values
- 23 (< 0.1%)
model22
ObjectDType- Null values
- 61,220 (100.0%)
- Unique values
- 18 (< 0.1%)
model23
ObjectDType- Null values
- 61,224 (100.0%)
- Unique values
- 16 (< 0.1%)
goods_code0
ObjectDType- Null values
- 0 (0.0%)
- Unique values
-
4,404 (7.2%)
This column has a high cardinality (> 40).
goods_code1
ObjectDType- Null values
- 30,267 (49.4%)
- Unique values
-
3,351 (5.5%)
This column has a high cardinality (> 40).
goods_code2
ObjectDType- Null values
- 52,467 (85.7%)
- Unique values
-
2,246 (3.7%)
This column has a high cardinality (> 40).
goods_code3
ObjectDType- Null values
- 58,223 (95.1%)
- Unique values
-
1,436 (2.3%)
This column has a high cardinality (> 40).
goods_code4
ObjectDType- Null values
- 59,813 (97.7%)
- Unique values
-
989 (1.6%)
This column has a high cardinality (> 40).
goods_code5
ObjectDType- Null values
- 60,366 (98.6%)
- Unique values
-
661 (1.1%)
This column has a high cardinality (> 40).
goods_code6
ObjectDType- Null values
- 60,632 (99.0%)
- Unique values
-
516 (0.8%)
This column has a high cardinality (> 40).
goods_code7
ObjectDType- Null values
- 60,778 (99.2%)
- Unique values
-
396 (0.6%)
This column has a high cardinality (> 40).
goods_code8
ObjectDType- Null values
- 60,874 (99.4%)
- Unique values
-
332 (0.5%)
This column has a high cardinality (> 40).
goods_code9
ObjectDType- Null values
- 60,939 (99.5%)
- Unique values
-
269 (0.4%)
This column has a high cardinality (> 40).
goods_code10
ObjectDType- Null values
- 60,995 (99.6%)
- Unique values
-
222 (0.4%)
This column has a high cardinality (> 40).
goods_code11
ObjectDType- Null values
- 61,034 (99.7%)
- Unique values
-
183 (0.3%)
This column has a high cardinality (> 40).
goods_code12
ObjectDType- Null values
- 61,074 (99.7%)
- Unique values
-
153 (0.2%)
This column has a high cardinality (> 40).
goods_code13
ObjectDType- Null values
- 61,105 (99.8%)
- Unique values
-
126 (0.2%)
This column has a high cardinality (> 40).
goods_code14
ObjectDType- Null values
- 61,123 (99.8%)
- Unique values
-
106 (0.2%)
This column has a high cardinality (> 40).
goods_code15
ObjectDType- Null values
- 61,143 (99.8%)
- Unique values
-
91 (0.1%)
This column has a high cardinality (> 40).
goods_code16
ObjectDType- Null values
- 61,160 (99.9%)
- Unique values
-
76 (0.1%)
This column has a high cardinality (> 40).
goods_code17
ObjectDType- Null values
- 61,174 (99.9%)
- Unique values
-
60 (< 0.1%)
This column has a high cardinality (> 40).
goods_code18
ObjectDType- Null values
- 61,187 (99.9%)
- Unique values
-
50 (< 0.1%)
This column has a high cardinality (> 40).
goods_code19
ObjectDType- Null values
- 61,194 (99.9%)
- Unique values
-
43 (< 0.1%)
This column has a high cardinality (> 40).
goods_code20
ObjectDType- Null values
- 61,203 (99.9%)
- Unique values
- 33 (< 0.1%)
goods_code21
ObjectDType- Null values
- 61,210 (99.9%)
- Unique values
- 27 (< 0.1%)
goods_code22
ObjectDType- Null values
- 61,219 (100.0%)
- Unique values
- 19 (< 0.1%)
goods_code23
ObjectDType- Null values
- 61,224 (100.0%)
- Unique values
- 16 (< 0.1%)
Nbr_of_prod_purchas0
Int64DType- Null values
- 0 (0.0%)
- Unique values
- 14 (< 0.1%)
- Mean ± Std
- 1.03 ± 0.365
- Median ± IQR
- 1 ± 0
- Min | Max
- 1 | 40
Nbr_of_prod_purchas1
Float64DType- Null values
- 30,267 (49.4%)
- Unique values
- 10 (< 0.1%)
- Mean ± Std
- 1.03 ± 0.265
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 10.0
Nbr_of_prod_purchas2
Float64DType- Null values
- 52,467 (85.7%)
- Unique values
- 10 (< 0.1%)
- Mean ± Std
- 1.07 ± 0.427
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 15.0
Nbr_of_prod_purchas3
Float64DType- Null values
- 58,223 (95.1%)
- Unique values
- 13 (< 0.1%)
- Mean ± Std
- 1.16 ± 0.876
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 28.0
Nbr_of_prod_purchas4
Float64DType- Null values
- 59,813 (97.7%)
- Unique values
- 9 (< 0.1%)
- Mean ± Std
- 1.24 ± 0.827
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 15.0
Nbr_of_prod_purchas5
Float64DType- Null values
- 60,366 (98.6%)
- Unique values
- 8 (< 0.1%)
- Mean ± Std
- 1.25 ± 1.09
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 24.0
Nbr_of_prod_purchas6
Float64DType- Null values
- 60,632 (99.0%)
- Unique values
- 9 (< 0.1%)
- Mean ± Std
- 1.28 ± 0.812
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 9.00
Nbr_of_prod_purchas7
Float64DType- Null values
- 60,778 (99.2%)
- Unique values
- 9 (< 0.1%)
- Mean ± Std
- 1.34 ± 1.09
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 14.0
Nbr_of_prod_purchas8
Float64DType- Null values
- 60,874 (99.4%)
- Unique values
- 10 (< 0.1%)
- Mean ± Std
- 1.42 ± 1.16
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 10.0
Nbr_of_prod_purchas9
Float64DType- Null values
- 60,939 (99.5%)
- Unique values
- 7 (< 0.1%)
- Mean ± Std
- 1.35 ± 0.920
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 8.00
Nbr_of_prod_purchas10
Float64DType- Null values
- 60,995 (99.6%)
- Unique values
- 9 (< 0.1%)
- Mean ± Std
- 1.39 ± 1.19
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 12.0
Nbr_of_prod_purchas11
Float64DType- Null values
- 61,034 (99.7%)
- Unique values
- 6 (< 0.1%)
- Mean ± Std
- 1.30 ± 0.853
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 6.00
Nbr_of_prod_purchas12
Float64DType- Null values
- 61,074 (99.7%)
- Unique values
- 4 (< 0.1%)
- Mean ± Std
- 1.19 ± 0.465
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 4.00
Nbr_of_prod_purchas13
Float64DType- Null values
- 61,105 (99.8%)
- Unique values
- 6 (< 0.1%)
- Mean ± Std
- 1.37 ± 1.18
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 12.0
Nbr_of_prod_purchas14
Float64DType- Null values
- 61,123 (99.8%)
- Unique values
- 6 (< 0.1%)
- Mean ± Std
- 1.32 ± 0.866
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 6.00
Nbr_of_prod_purchas15
Float64DType- Null values
- 61,143 (99.8%)
- Unique values
- 6 (< 0.1%)
- Mean ± Std
- 1.32 ± 0.807
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 6.00
Nbr_of_prod_purchas16
Float64DType- Null values
- 61,160 (99.9%)
- Unique values
- 5 (< 0.1%)
- Mean ± Std
- 1.47 ± 1.38
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 12.0
Nbr_of_prod_purchas17
Float64DType- Null values
- 61,174 (99.9%)
- Unique values
- 4 (< 0.1%)
- Mean ± Std
- 1.39 ± 1.87
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 16.0
Nbr_of_prod_purchas18
Float64DType- Null values
- 61,187 (99.9%)
- Unique values
- 4 (< 0.1%)
- Mean ± Std
- 1.20 ± 0.810
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 6.00
Nbr_of_prod_purchas19
Float64DType- Null values
- 61,194 (99.9%)
- Unique values
- 5 (< 0.1%)
- Mean ± Std
- 1.40 ± 1.06
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 7.00
Nbr_of_prod_purchas20
Float64DType- Null values
- 61,203 (99.9%)
- Unique values
- 3 (< 0.1%)
- Mean ± Std
- 1.18 ± 0.563
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 4.00
Nbr_of_prod_purchas21
Float64DType- Null values
- 61,210 (99.9%)
- Unique values
- 4 (< 0.1%)
- Mean ± Std
- 1.48 ± 1.21
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 7.00
Nbr_of_prod_purchas22
Float64DType- Null values
- 61,219 (100.0%)
- Unique values
- 4 (< 0.1%)
- Mean ± Std
- 1.27 ± 0.767
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 4.00
Nbr_of_prod_purchas23
Float64DType- Null values
- 61,224 (100.0%)
- Unique values
- 2 (< 0.1%)
- Mean ± Std
- 1.29 ± 0.470
- Median ± IQR
- 1.00 ± 1.00
- Min | Max
- 1.00 | 2.00
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
| Column | Column name | dtype | Is sorted | Null values | Unique values | Mean | Std | Min | Median | Max |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | basket_ID | Int64DType | True | 0 (0.0%) | 61241 (100.0%) | 3.82e+04 | 2.21e+04 | 0 | 38,158 | 76,543 |
| 1 | item0 | ObjectDType | False | 0 (0.0%) | 133 (0.2%) | |||||
| 2 | item1 | ObjectDType | False | 30267 (49.4%) | 130 (0.2%) | |||||
| 3 | item2 | ObjectDType | False | 52467 (85.7%) | 121 (0.2%) | |||||
| 4 | item3 | ObjectDType | False | 58223 (95.1%) | 119 (0.2%) | |||||
| 5 | item4 | ObjectDType | False | 59813 (97.7%) | 98 (0.2%) | |||||
| 6 | item5 | ObjectDType | False | 60366 (98.6%) | 91 (0.1%) | |||||
| 7 | item6 | ObjectDType | False | 60632 (99.0%) | 81 (0.1%) | |||||
| 8 | item7 | ObjectDType | False | 60778 (99.2%) | 76 (0.1%) | |||||
| 9 | item8 | ObjectDType | False | 60874 (99.4%) | 71 (0.1%) | |||||
| 10 | item9 | ObjectDType | False | 60939 (99.5%) | 58 (< 0.1%) | |||||
| 11 | item10 | ObjectDType | False | 60995 (99.6%) | 61 (< 0.1%) | |||||
| 12 | item11 | ObjectDType | False | 61034 (99.7%) | 49 (< 0.1%) | |||||
| 13 | item12 | ObjectDType | False | 61074 (99.7%) | 47 (< 0.1%) | |||||
| 14 | item13 | ObjectDType | False | 61105 (99.8%) | 47 (< 0.1%) | |||||
| 15 | item14 | ObjectDType | False | 61123 (99.8%) | 44 (< 0.1%) | |||||
| 16 | item15 | ObjectDType | False | 61143 (99.8%) | 36 (< 0.1%) | |||||
| 17 | item16 | ObjectDType | False | 61160 (99.9%) | 35 (< 0.1%) | |||||
| 18 | item17 | ObjectDType | False | 61174 (99.9%) | 29 (< 0.1%) | |||||
| 19 | item18 | ObjectDType | False | 61187 (99.9%) | 24 (< 0.1%) | |||||
| 20 | item19 | ObjectDType | False | 61194 (99.9%) | 20 (< 0.1%) | |||||
| 21 | item20 | ObjectDType | False | 61203 (99.9%) | 22 (< 0.1%) | |||||
| 22 | item21 | ObjectDType | False | 61210 (99.9%) | 15 (< 0.1%) | |||||
| 23 | item22 | ObjectDType | False | 61219 (100.0%) | 15 (< 0.1%) | |||||
| 24 | item23 | ObjectDType | False | 61224 (100.0%) | 11 (< 0.1%) | |||||
| 25 | cash_price0 | Int64DType | False | 0 (0.0%) | 1102 (1.8%) | 1.06e+03 | 679. | 2 | 949 | 18,349 |
| 26 | cash_price1 | Float64DType | False | 30267 (49.4%) | 689 (1.1%) | 180. | 379. | 0.00 | 30.0 | 6.50e+03 |
| 27 | cash_price2 | Float64DType | False | 52467 (85.7%) | 511 (0.8%) | 184. | 369. | 0.00 | 30.0 | 6.00e+03 |
| 28 | cash_price3 | Float64DType | False | 58223 (95.1%) | 372 (0.6%) | 161. | 298. | 0.00 | 40.0 | 2.85e+03 |
| 29 | cash_price4 | Float64DType | False | 59813 (97.7%) | 283 (0.5%) | 187. | 355. | 0.00 | 52.0 | 3.60e+03 |
| 30 | cash_price5 | Float64DType | False | 60366 (98.6%) | 216 (0.4%) | 161. | 297. | 0.00 | 50.0 | 3.00e+03 |
| 31 | cash_price6 | Float64DType | False | 60632 (99.0%) | 173 (0.3%) | 131. | 268. | 0.00 | 50.0 | 4.20e+03 |
| 32 | cash_price7 | Float64DType | False | 60778 (99.2%) | 142 (0.2%) | 127. | 261. | 0.00 | 45.0 | 3.00e+03 |
| 33 | cash_price8 | Float64DType | False | 60874 (99.4%) | 138 (0.2%) | 128. | 274. | 0.00 | 44.0 | 2.40e+03 |
| 34 | cash_price9 | Float64DType | False | 60939 (99.5%) | 104 (0.2%) | 93.5 | 178. | 0.00 | 35.0 | 1.40e+03 |
| 35 | cash_price10 | Float64DType | False | 60995 (99.6%) | 97 (0.2%) | 101. | 205. | 0.00 | 30.0 | 1.90e+03 |
| 36 | cash_price11 | Float64DType | False | 61034 (99.7%) | 96 (0.2%) | 107. | 249. | 0.00 | 30.0 | 2.16e+03 |
| 37 | cash_price12 | Float64DType | False | 61074 (99.7%) | 77 (0.1%) | 73.3 | 114. | 0.00 | 25.0 | 799. |
| 38 | cash_price13 | Float64DType | False | 61105 (99.8%) | 76 (0.1%) | 93.8 | 168. | 0.00 | 39.0 | 1.30e+03 |
| 39 | cash_price14 | Float64DType | False | 61123 (99.8%) | 57 (< 0.1%) | 67.3 | 101. | 0.00 | 30.0 | 599. |
| 40 | cash_price15 | Float64DType | False | 61143 (99.8%) | 54 (< 0.1%) | 88.3 | 187. | 0.00 | 34.0 | 1.50e+03 |
| 41 | cash_price16 | Float64DType | False | 61160 (99.9%) | 54 (< 0.1%) | 110. | 213. | 0.00 | 40.0 | 1.55e+03 |
| 42 | cash_price17 | Float64DType | False | 61174 (99.9%) | 48 (< 0.1%) | 99.6 | 154. | 0.00 | 32.0 | 799. |
| 43 | cash_price18 | Float64DType | False | 61187 (99.9%) | 42 (< 0.1%) | 84.3 | 152. | 0.00 | 35.0 | 999. |
| 44 | cash_price19 | Float64DType | False | 61194 (99.9%) | 37 (< 0.1%) | 98.2 | 298. | 0.00 | 30.0 | 2.01e+03 |
| 45 | cash_price20 | Float64DType | False | 61203 (99.9%) | 26 (< 0.1%) | 53.8 | 88.1 | 4.00 | 18.0 | 419. |
| 46 | cash_price21 | Float64DType | False | 61210 (99.9%) | 25 (< 0.1%) | 129. | 378. | 0.00 | 25.0 | 2.09e+03 |
| 47 | cash_price22 | Float64DType | False | 61219 (100.0%) | 21 (< 0.1%) | 129. | 213. | 0.00 | 25.0 | 720. |
| 48 | cash_price23 | Float64DType | False | 61224 (100.0%) | 15 (< 0.1%) | 136. | 260. | 4.00 | 15.0 | 898. |
| 49 | make0 | ObjectDType | False | 685 (1.1%) | 346 (0.6%) | |||||
| 50 | make1 | ObjectDType | False | 30594 (50.0%) | 311 (0.5%) | |||||
| 51 | make2 | ObjectDType | False | 52577 (85.9%) | 289 (0.5%) | |||||
| 52 | make3 | ObjectDType | False | 58257 (95.1%) | 243 (0.4%) | |||||
| 53 | make4 | ObjectDType | False | 59832 (97.7%) | 202 (0.3%) | |||||
| 54 | make5 | ObjectDType | False | 60379 (98.6%) | 149 (0.2%) | |||||
| 55 | make6 | ObjectDType | False | 60642 (99.0%) | 131 (0.2%) | |||||
| 56 | make7 | ObjectDType | False | 60788 (99.3%) | 122 (0.2%) | |||||
| 57 | make8 | ObjectDType | False | 60884 (99.4%) | 102 (0.2%) | |||||
| 58 | make9 | ObjectDType | False | 60949 (99.5%) | 85 (0.1%) | |||||
| 59 | make10 | ObjectDType | False | 61003 (99.6%) | 79 (0.1%) | |||||
| 60 | make11 | ObjectDType | False | 61042 (99.7%) | 67 (0.1%) | |||||
| 61 | make12 | ObjectDType | False | 61081 (99.7%) | 52 (< 0.1%) | |||||
| 62 | make13 | ObjectDType | False | 61110 (99.8%) | 53 (< 0.1%) | |||||
| 63 | make14 | ObjectDType | False | 61128 (99.8%) | 46 (< 0.1%) | |||||
| 64 | make15 | ObjectDType | False | 61146 (99.8%) | 35 (< 0.1%) | |||||
| 65 | make16 | ObjectDType | False | 61163 (99.9%) | 31 (< 0.1%) | |||||
| 66 | make17 | ObjectDType | False | 61175 (99.9%) | 22 (< 0.1%) | |||||
| 67 | make18 | ObjectDType | False | 61188 (99.9%) | 25 (< 0.1%) | |||||
| 68 | make19 | ObjectDType | False | 61195 (99.9%) | 20 (< 0.1%) | |||||
| 69 | make20 | ObjectDType | False | 61204 (99.9%) | 17 (< 0.1%) | |||||
| 70 | make21 | ObjectDType | False | 61211 (100.0%) | 12 (< 0.1%) | |||||
| 71 | make22 | ObjectDType | False | 61220 (100.0%) | 12 (< 0.1%) | |||||
| 72 | make23 | ObjectDType | False | 61224 (100.0%) | 9 (< 0.1%) | |||||
| 73 | model0 | ObjectDType | False | 685 (1.1%) | 2624 (4.3%) | |||||
| 74 | model1 | ObjectDType | False | 30594 (50.0%) | 2101 (3.4%) | |||||
| 75 | model2 | ObjectDType | False | 52577 (85.9%) | 1507 (2.5%) | |||||
| 76 | model3 | ObjectDType | False | 58257 (95.1%) | 983 (1.6%) | |||||
| 77 | model4 | ObjectDType | False | 59832 (97.7%) | 658 (1.1%) | |||||
| 78 | model5 | ObjectDType | False | 60379 (98.6%) | 437 (0.7%) | |||||
| 79 | model6 | ObjectDType | False | 60642 (99.0%) | 333 (0.5%) | |||||
| 80 | model7 | ObjectDType | False | 60788 (99.3%) | 263 (0.4%) | |||||
| 81 | model8 | ObjectDType | False | 60884 (99.4%) | 212 (0.3%) | |||||
| 82 | model9 | ObjectDType | False | 60949 (99.5%) | 184 (0.3%) | |||||
| 83 | model10 | ObjectDType | False | 61003 (99.6%) | 147 (0.2%) | |||||
| 84 | model11 | ObjectDType | False | 61042 (99.7%) | 122 (0.2%) | |||||
| 85 | model12 | ObjectDType | False | 61081 (99.7%) | 99 (0.2%) | |||||
| 86 | model13 | ObjectDType | False | 61110 (99.8%) | 81 (0.1%) | |||||
| 87 | model14 | ObjectDType | False | 61128 (99.8%) | 73 (0.1%) | |||||
| 88 | model15 | ObjectDType | False | 61146 (99.8%) | 60 (< 0.1%) | |||||
| 89 | model16 | ObjectDType | False | 61163 (99.9%) | 53 (< 0.1%) | |||||
| 90 | model17 | ObjectDType | False | 61175 (99.9%) | 41 (< 0.1%) | |||||
| 91 | model18 | ObjectDType | False | 61188 (99.9%) | 36 (< 0.1%) | |||||
| 92 | model19 | ObjectDType | False | 61195 (99.9%) | 33 (< 0.1%) | |||||
| 93 | model20 | ObjectDType | False | 61204 (99.9%) | 25 (< 0.1%) | |||||
| 94 | model21 | ObjectDType | False | 61211 (100.0%) | 23 (< 0.1%) | |||||
| 95 | model22 | ObjectDType | False | 61220 (100.0%) | 18 (< 0.1%) | |||||
| 96 | model23 | ObjectDType | False | 61224 (100.0%) | 16 (< 0.1%) | |||||
| 97 | goods_code0 | ObjectDType | False | 0 (0.0%) | 4404 (7.2%) | |||||
| 98 | goods_code1 | ObjectDType | False | 30267 (49.4%) | 3351 (5.5%) | |||||
| 99 | goods_code2 | ObjectDType | False | 52467 (85.7%) | 2246 (3.7%) | |||||
| 100 | goods_code3 | ObjectDType | False | 58223 (95.1%) | 1436 (2.3%) | |||||
| 101 | goods_code4 | ObjectDType | False | 59813 (97.7%) | 989 (1.6%) | |||||
| 102 | goods_code5 | ObjectDType | False | 60366 (98.6%) | 661 (1.1%) | |||||
| 103 | goods_code6 | ObjectDType | False | 60632 (99.0%) | 516 (0.8%) | |||||
| 104 | goods_code7 | ObjectDType | False | 60778 (99.2%) | 396 (0.6%) | |||||
| 105 | goods_code8 | ObjectDType | False | 60874 (99.4%) | 332 (0.5%) | |||||
| 106 | goods_code9 | ObjectDType | False | 60939 (99.5%) | 269 (0.4%) | |||||
| 107 | goods_code10 | ObjectDType | False | 60995 (99.6%) | 222 (0.4%) | |||||
| 108 | goods_code11 | ObjectDType | False | 61034 (99.7%) | 183 (0.3%) | |||||
| 109 | goods_code12 | ObjectDType | False | 61074 (99.7%) | 153 (0.2%) | |||||
| 110 | goods_code13 | ObjectDType | False | 61105 (99.8%) | 126 (0.2%) | |||||
| 111 | goods_code14 | ObjectDType | False | 61123 (99.8%) | 106 (0.2%) | |||||
| 112 | goods_code15 | ObjectDType | False | 61143 (99.8%) | 91 (0.1%) | |||||
| 113 | goods_code16 | ObjectDType | False | 61160 (99.9%) | 76 (0.1%) | |||||
| 114 | goods_code17 | ObjectDType | False | 61174 (99.9%) | 60 (< 0.1%) | |||||
| 115 | goods_code18 | ObjectDType | False | 61187 (99.9%) | 50 (< 0.1%) | |||||
| 116 | goods_code19 | ObjectDType | False | 61194 (99.9%) | 43 (< 0.1%) | |||||
| 117 | goods_code20 | ObjectDType | False | 61203 (99.9%) | 33 (< 0.1%) | |||||
| 118 | goods_code21 | ObjectDType | False | 61210 (99.9%) | 27 (< 0.1%) | |||||
| 119 | goods_code22 | ObjectDType | False | 61219 (100.0%) | 19 (< 0.1%) | |||||
| 120 | goods_code23 | ObjectDType | False | 61224 (100.0%) | 16 (< 0.1%) | |||||
| 121 | Nbr_of_prod_purchas0 | Int64DType | False | 0 (0.0%) | 14 (< 0.1%) | 1.03 | 0.365 | 1 | 1 | 40 |
| 122 | Nbr_of_prod_purchas1 | Float64DType | False | 30267 (49.4%) | 10 (< 0.1%) | 1.03 | 0.265 | 1.00 | 1.00 | 10.0 |
| 123 | Nbr_of_prod_purchas2 | Float64DType | False | 52467 (85.7%) | 10 (< 0.1%) | 1.07 | 0.427 | 1.00 | 1.00 | 15.0 |
| 124 | Nbr_of_prod_purchas3 | Float64DType | False | 58223 (95.1%) | 13 (< 0.1%) | 1.16 | 0.876 | 1.00 | 1.00 | 28.0 |
| 125 | Nbr_of_prod_purchas4 | Float64DType | False | 59813 (97.7%) | 9 (< 0.1%) | 1.24 | 0.827 | 1.00 | 1.00 | 15.0 |
| 126 | Nbr_of_prod_purchas5 | Float64DType | False | 60366 (98.6%) | 8 (< 0.1%) | 1.25 | 1.09 | 1.00 | 1.00 | 24.0 |
| 127 | Nbr_of_prod_purchas6 | Float64DType | False | 60632 (99.0%) | 9 (< 0.1%) | 1.28 | 0.812 | 1.00 | 1.00 | 9.00 |
| 128 | Nbr_of_prod_purchas7 | Float64DType | False | 60778 (99.2%) | 9 (< 0.1%) | 1.34 | 1.09 | 1.00 | 1.00 | 14.0 |
| 129 | Nbr_of_prod_purchas8 | Float64DType | False | 60874 (99.4%) | 10 (< 0.1%) | 1.42 | 1.16 | 1.00 | 1.00 | 10.0 |
| 130 | Nbr_of_prod_purchas9 | Float64DType | False | 60939 (99.5%) | 7 (< 0.1%) | 1.35 | 0.920 | 1.00 | 1.00 | 8.00 |
| 131 | Nbr_of_prod_purchas10 | Float64DType | False | 60995 (99.6%) | 9 (< 0.1%) | 1.39 | 1.19 | 1.00 | 1.00 | 12.0 |
| 132 | Nbr_of_prod_purchas11 | Float64DType | False | 61034 (99.7%) | 6 (< 0.1%) | 1.30 | 0.853 | 1.00 | 1.00 | 6.00 |
| 133 | Nbr_of_prod_purchas12 | Float64DType | False | 61074 (99.7%) | 4 (< 0.1%) | 1.19 | 0.465 | 1.00 | 1.00 | 4.00 |
| 134 | Nbr_of_prod_purchas13 | Float64DType | False | 61105 (99.8%) | 6 (< 0.1%) | 1.37 | 1.18 | 1.00 | 1.00 | 12.0 |
| 135 | Nbr_of_prod_purchas14 | Float64DType | False | 61123 (99.8%) | 6 (< 0.1%) | 1.32 | 0.866 | 1.00 | 1.00 | 6.00 |
| 136 | Nbr_of_prod_purchas15 | Float64DType | False | 61143 (99.8%) | 6 (< 0.1%) | 1.32 | 0.807 | 1.00 | 1.00 | 6.00 |
| 137 | Nbr_of_prod_purchas16 | Float64DType | False | 61160 (99.9%) | 5 (< 0.1%) | 1.47 | 1.38 | 1.00 | 1.00 | 12.0 |
| 138 | Nbr_of_prod_purchas17 | Float64DType | False | 61174 (99.9%) | 4 (< 0.1%) | 1.39 | 1.87 | 1.00 | 1.00 | 16.0 |
| 139 | Nbr_of_prod_purchas18 | Float64DType | False | 61187 (99.9%) | 4 (< 0.1%) | 1.20 | 0.810 | 1.00 | 1.00 | 6.00 |
| 140 | Nbr_of_prod_purchas19 | Float64DType | False | 61194 (99.9%) | 5 (< 0.1%) | 1.40 | 1.06 | 1.00 | 1.00 | 7.00 |
| 141 | Nbr_of_prod_purchas20 | Float64DType | False | 61203 (99.9%) | 3 (< 0.1%) | 1.18 | 0.563 | 1.00 | 1.00 | 4.00 |
| 142 | Nbr_of_prod_purchas21 | Float64DType | False | 61210 (99.9%) | 4 (< 0.1%) | 1.48 | 1.21 | 1.00 | 1.00 | 7.00 |
| 143 | Nbr_of_prod_purchas22 | Float64DType | False | 61219 (100.0%) | 4 (< 0.1%) | 1.27 | 0.767 | 1.00 | 1.00 | 4.00 |
| 144 | Nbr_of_prod_purchas23 | Float64DType | False | 61224 (100.0%) | 2 (< 0.1%) | 1.29 | 0.470 | 1.00 | 1.00 | 2.00 |
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
max_plot_columns
limit set for the TableReport during report creation.
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
max_association_columns parameter.
Please enable javascript
The skrub table reports need javascript to display correctly. If you are displaying a report in a Jupyter notebook and you see this message, you may need to re-execute the cell or to trust the notebook (button on the top right or "File > Trust notebook").
Look at the “Stats” section of the TableReport above. Does anything strike you?
Not only did we create 144 columns, but most of these columns are filled with NaN, which is very inefficient for learning!
This is because each basket contains a variable number of products, up to 24, and we created one column for each product attribute, for each position (up to 24) in the dataframe.
Moreover, if we wanted to replace text columns with encodings, we would create
\(d \times 24 \times 2\) columns (encoding of dimensionality \(d\), for
24 products, for the "item" and "make" columns), which would explode the
memory usage.
AggJoiner#
Let’s now see how the AggJoiner can help us solve this. We begin with splitting our
basket dataset in a training and testing set.
from sklearn.model_selection import train_test_split
X, y = baskets[["ID"]], baskets["fraud_flag"]
X_train, X_test, y_train, y_test = train_test_split(X, y, stratify=y, test_size=0.1)
X_train.shape, y_train.shape
((55116, 1), (55116,))
Before aggregating our product dataframe, we need to vectorize our categorical columns. To do so, we use:
MinHashEncoderon “item” and “model” columns, because they both expose typos and text similarities.OrdinalEncoderon “make” and “goods_code” columns, because they consist in orthogonal categories.
We bring this logic into a TableVectorizer to vectorize these columns in a
single step.
See this example
for more details about these encoding choices.
from sklearn.preprocessing import OrdinalEncoder
from skrub import MinHashEncoder, TableVectorizer
vectorizer = TableVectorizer(
high_cardinality=MinHashEncoder(), # encode ["item", "model"]
specific_transformers=[
(OrdinalEncoder(), ["make", "goods_code"]),
],
)
products_transformed = vectorizer.fit_transform(products)
TableReport(products_transformed)
| basket_ID | item_00 | item_01 | item_02 | item_03 | item_04 | item_05 | item_06 | item_07 | item_08 | item_09 | item_10 | item_11 | item_12 | item_13 | item_14 | item_15 | item_16 | item_17 | item_18 | item_19 | item_20 | item_21 | item_22 | item_23 | item_24 | item_25 | item_26 | item_27 | item_28 | item_29 | cash_price | make | model_00 | model_01 | model_02 | model_03 | model_04 | model_05 | model_06 | model_07 | model_08 | model_09 | model_10 | model_11 | model_12 | model_13 | model_14 | model_15 | model_16 | model_17 | model_18 | model_19 | model_20 | model_21 | model_22 | model_23 | model_24 | model_25 | model_26 | model_27 | model_28 | model_29 | goods_code | Nbr_of_prod_purchas | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 5.11e+04 | -2.12e+09 | -2.09e+09 | -2.09e+09 | -2.10e+09 | -2.05e+09 | -2.07e+09 | -2.08e+09 | -2.01e+09 | -2.07e+09 | -2.09e+09 | -2.08e+09 | -2.14e+09 | -2.06e+09 | -2.10e+09 | -2.09e+09 | -2.12e+09 | -2.11e+09 | -2.04e+09 | -2.14e+09 | -2.13e+09 | -2.11e+09 | -2.14e+09 | -2.06e+09 | -2.08e+09 | -2.14e+09 | -2.02e+09 | -1.84e+09 | -2.12e+09 | -2.12e+09 | -2.12e+09 | 409. | 24.0 | -2.09e+09 | -2.14e+09 | -2.12e+09 | -2.12e+09 | -2.04e+09 | -2.14e+09 | -2.14e+09 | -2.12e+09 | -2.07e+09 | -2.07e+09 | -2.08e+09 | -2.13e+09 | -2.13e+09 | -2.11e+09 | -2.13e+09 | -2.14e+09 | -2.10e+09 | -2.14e+09 | -2.05e+09 | -2.14e+09 | -2.11e+09 | -2.09e+09 | -2.11e+09 | -2.09e+09 | -2.07e+09 | -2.10e+09 | -2.07e+09 | -2.11e+09 | -2.13e+09 | -1.99e+09 | 8.26e+03 | 1.00 |
| 9 | 4.18e+04 | -2.12e+09 | -1.62e+09 | -1.80e+09 | -2.07e+09 | -2.05e+09 | -2.06e+09 | -1.41e+09 | -2.00e+09 | -1.86e+09 | -2.06e+09 | -1.95e+09 | -2.14e+09 | -1.98e+09 | -2.10e+09 | -1.90e+09 | -1.89e+09 | -2.07e+09 | -2.04e+09 | -1.96e+09 | -2.03e+09 | -2.10e+09 | -2.05e+09 | -2.06e+09 | -2.08e+09 | -2.09e+09 | -1.69e+09 | -1.84e+09 | -2.12e+09 | -2.12e+09 | -1.93e+09 | 1.19e+03 | 24.0 | -2.07e+09 | -2.09e+09 | -2.12e+09 | -2.08e+09 | -1.98e+09 | -2.12e+09 | -2.08e+09 | -2.09e+09 | -2.07e+09 | -2.11e+09 | -2.10e+09 | -2.12e+09 | -1.99e+09 | -2.11e+09 | -2.14e+09 | -2.13e+09 | -2.06e+09 | -2.13e+09 | -2.06e+09 | -2.14e+09 | -2.14e+09 | -2.14e+09 | -2.02e+09 | -2.15e+09 | -2.14e+09 | -2.10e+09 | -2.04e+09 | -2.15e+09 | -2.13e+09 | -1.96e+09 | 8.72e+03 | 1.00 |
| 11 | 3.94e+04 | -2.12e+09 | -1.62e+09 | -1.80e+09 | -2.07e+09 | -2.05e+09 | -2.06e+09 | -1.41e+09 | -2.00e+09 | -1.86e+09 | -2.06e+09 | -1.95e+09 | -2.14e+09 | -1.98e+09 | -2.10e+09 | -1.90e+09 | -1.89e+09 | -2.07e+09 | -2.04e+09 | -1.96e+09 | -2.03e+09 | -2.10e+09 | -2.05e+09 | -2.06e+09 | -2.08e+09 | -2.09e+09 | -1.69e+09 | -1.84e+09 | -2.12e+09 | -2.12e+09 | -1.93e+09 | 898. | 24.0 | -2.07e+09 | -2.14e+09 | -2.13e+09 | -2.11e+09 | -2.10e+09 | -2.10e+09 | -2.08e+09 | -2.12e+09 | -2.07e+09 | -2.09e+09 | -2.08e+09 | -2.07e+09 | -2.05e+09 | -2.10e+09 | -2.10e+09 | -2.03e+09 | -2.05e+09 | -2.13e+09 | -2.06e+09 | -2.14e+09 | -2.14e+09 | -2.14e+09 | -2.10e+09 | -2.15e+09 | -2.14e+09 | -2.11e+09 | -2.04e+09 | -2.05e+09 | -2.15e+09 | -2.11e+09 | 8.72e+03 | 1.00 |
| 15 | 3.86e+04 | -2.12e+09 | -2.09e+09 | -2.09e+09 | -2.10e+09 | -2.05e+09 | -2.07e+09 | -2.08e+09 | -2.01e+09 | -2.07e+09 | -2.09e+09 | -2.08e+09 | -2.14e+09 | -2.06e+09 | -2.10e+09 | -2.09e+09 | -2.12e+09 | -2.11e+09 | -2.04e+09 | -2.14e+09 | -2.13e+09 | -2.11e+09 | -2.14e+09 | -2.06e+09 | -2.08e+09 | -2.14e+09 | -2.02e+09 | -1.84e+09 | -2.12e+09 | -2.12e+09 | -2.12e+09 | 379. | 24.0 | -2.09e+09 | -2.12e+09 | -2.12e+09 | -2.15e+09 | -2.08e+09 | -2.14e+09 | -2.14e+09 | -2.01e+09 | -2.14e+09 | -2.05e+09 | -2.08e+09 | -2.13e+09 | -2.13e+09 | -2.11e+09 | -2.13e+09 | -2.12e+09 | -2.10e+09 | -2.14e+09 | -2.08e+09 | -2.14e+09 | -2.11e+09 | -2.12e+09 | -2.08e+09 | -2.09e+09 | -2.07e+09 | -2.10e+09 | -2.07e+09 | -2.11e+09 | -2.09e+09 | -1.99e+09 | 8.26e+03 | 1.00 |
| 16 | 7.03e+04 | -2.12e+09 | -1.62e+09 | -1.80e+09 | -2.07e+09 | -2.05e+09 | -2.06e+09 | -1.41e+09 | -2.00e+09 | -1.86e+09 | -2.06e+09 | -1.95e+09 | -2.14e+09 | -1.98e+09 | -2.10e+09 | -1.90e+09 | -1.89e+09 | -2.07e+09 | -2.04e+09 | -1.96e+09 | -2.03e+09 | -2.10e+09 | -2.05e+09 | -2.06e+09 | -2.08e+09 | -2.09e+09 | -1.69e+09 | -1.84e+09 | -2.12e+09 | -2.12e+09 | -1.93e+09 | 1.90e+03 | 24.0 | -2.11e+09 | -2.09e+09 | -2.14e+09 | -2.12e+09 | -2.07e+09 | -2.10e+09 | -2.08e+09 | -2.09e+09 | -2.07e+09 | -2.14e+09 | -2.10e+09 | -2.11e+09 | -2.12e+09 | -2.10e+09 | -2.10e+09 | -2.11e+09 | -2.06e+09 | -2.13e+09 | -2.06e+09 | -2.14e+09 | -2.14e+09 | -2.14e+09 | -2.02e+09 | -2.15e+09 | -2.07e+09 | -2.10e+09 | -2.04e+09 | -2.07e+09 | -2.13e+09 | -2.01e+09 | 1.07e+04 | 1.00 |
| 163,352 | 4.26e+04 | -1.94e+09 | -2.14e+09 | -2.04e+09 | -1.95e+09 | -1.96e+09 | -2.12e+09 | -1.99e+09 | -2.00e+09 | -2.05e+09 | -2.13e+09 | -1.99e+09 | -2.14e+09 | -1.98e+09 | -2.07e+09 | -1.96e+09 | -2.10e+09 | -2.00e+09 | -1.88e+09 | -1.96e+09 | -2.14e+09 | -2.06e+09 | -2.11e+09 | -2.11e+09 | -1.79e+09 | -2.09e+09 | -2.14e+09 | -2.02e+09 | -1.85e+09 | -1.86e+09 | -2.08e+09 | 259. | 546. | -1.99e+09 | -2.02e+09 | -1.99e+09 | -2.12e+09 | -1.99e+09 | -2.10e+09 | -2.13e+09 | -1.99e+09 | -2.08e+09 | -2.11e+09 | -2.09e+09 | -2.09e+09 | -2.13e+09 | -2.12e+09 | -2.14e+09 | -2.14e+09 | -2.08e+09 | -2.15e+09 | -2.08e+09 | -2.12e+09 | -1.97e+09 | -2.14e+09 | -2.13e+09 | -2.15e+09 | -2.14e+09 | -2.09e+09 | -2.12e+09 | -2.15e+09 | -2.14e+09 | -1.97e+09 | 2.19e+03 | 1.00 |
| 163,353 | 4.26e+04 | -1.94e+09 | -2.14e+09 | -1.81e+09 | -2.06e+09 | -1.96e+09 | -2.12e+09 | -2.00e+09 | -2.01e+09 | -1.99e+09 | -2.13e+09 | -1.99e+09 | -2.05e+09 | -1.83e+09 | -1.88e+09 | -1.61e+09 | -2.10e+09 | -1.43e+09 | -2.02e+09 | -1.99e+09 | -2.13e+09 | -1.88e+09 | -2.11e+09 | -2.11e+09 | -2.00e+09 | -2.03e+09 | -2.14e+09 | -2.02e+09 | -2.15e+09 | -2.01e+09 | -2.08e+09 | 949. | 338. | -2.14e+09 | -2.14e+09 | -2.12e+09 | -2.14e+09 | -2.06e+09 | -2.10e+09 | -2.10e+09 | -2.09e+09 | -2.12e+09 | -2.09e+09 | -2.12e+09 | -2.12e+09 | -2.09e+09 | -2.11e+09 | -2.14e+09 | -2.13e+09 | -2.06e+09 | -2.10e+09 | -2.05e+09 | -2.13e+09 | -2.04e+09 | -2.11e+09 | -2.10e+09 | -2.05e+09 | -2.13e+09 | -2.04e+09 | -2.11e+09 | -2.15e+09 | -2.09e+09 | -2.13e+09 | 8.91e+03 | 1.00 |
| 163,354 | 4.36e+04 | -2.12e+09 | -1.62e+09 | -1.80e+09 | -2.07e+09 | -2.05e+09 | -2.06e+09 | -1.41e+09 | -2.00e+09 | -1.86e+09 | -2.06e+09 | -1.95e+09 | -2.14e+09 | -1.98e+09 | -2.10e+09 | -1.90e+09 | -1.89e+09 | -2.07e+09 | -2.04e+09 | -1.96e+09 | -2.03e+09 | -2.10e+09 | -2.05e+09 | -2.06e+09 | -2.08e+09 | -2.09e+09 | -1.69e+09 | -1.84e+09 | -2.12e+09 | -2.12e+09 | -1.93e+09 | 1.10e+03 | 24.0 | -2.12e+09 | -2.12e+09 | -2.12e+09 | -2.12e+09 | -2.11e+09 | -2.10e+09 | -2.14e+09 | -2.09e+09 | -2.12e+09 | -2.11e+09 | -2.10e+09 | -2.07e+09 | -2.12e+09 | -2.10e+09 | -2.10e+09 | -2.03e+09 | -2.14e+09 | -2.07e+09 | -2.04e+09 | -2.14e+09 | -2.10e+09 | -2.14e+09 | -2.05e+09 | -2.00e+09 | -2.07e+09 | -2.11e+09 | -2.11e+09 | -2.14e+09 | -2.14e+09 | -2.07e+09 | 1.00e+04 | 1.00 |
| 163,355 | 4.36e+04 | -2.12e+09 | -1.62e+09 | -1.80e+09 | -2.07e+09 | -2.05e+09 | -2.06e+09 | -1.41e+09 | -2.00e+09 | -1.86e+09 | -2.06e+09 | -1.95e+09 | -2.14e+09 | -1.98e+09 | -2.10e+09 | -1.90e+09 | -1.89e+09 | -2.07e+09 | -2.04e+09 | -1.96e+09 | -2.03e+09 | -2.10e+09 | -2.05e+09 | -2.06e+09 | -2.08e+09 | -2.09e+09 | -1.69e+09 | -1.84e+09 | -2.12e+09 | -2.12e+09 | -1.93e+09 | 2.10e+03 | 24.0 | -2.12e+09 | -2.14e+09 | -2.14e+09 | -2.04e+09 | -2.12e+09 | -2.10e+09 | -2.12e+09 | -2.02e+09 | -2.12e+09 | -2.14e+09 | -2.07e+09 | -2.11e+09 | -2.12e+09 | -2.13e+09 | -2.13e+09 | -2.12e+09 | -2.04e+09 | -2.13e+09 | -2.12e+09 | -2.14e+09 | -2.10e+09 | -2.08e+09 | -2.02e+09 | -2.09e+09 | -2.14e+09 | -2.10e+09 | -2.11e+09 | -2.13e+09 | -2.05e+09 | -2.10e+09 | 7.79e+03 | 1.00 |
| 163,356 | 6.83e+04 | -2.13e+09 | -2.10e+09 | -2.14e+09 | -2.02e+09 | -2.06e+09 | -1.88e+09 | -2.12e+09 | -2.11e+09 | -2.09e+09 | -2.06e+09 | -2.06e+09 | -2.14e+09 | -2.12e+09 | -2.10e+09 | -1.99e+09 | -2.01e+09 | -2.01e+09 | -2.13e+09 | -2.02e+09 | -2.13e+09 | -2.07e+09 | -2.14e+09 | -2.06e+09 | -2.13e+09 | -2.10e+09 | -2.11e+09 | -2.15e+09 | -1.72e+09 | -2.14e+09 | -2.07e+09 | 799. | 337. | -2.14e+09 | -2.09e+09 | -2.07e+09 | -2.12e+09 | -2.11e+09 | -2.12e+09 | -2.14e+09 | -2.09e+09 | -2.12e+09 | -2.13e+09 | -2.13e+09 | -2.14e+09 | -2.08e+09 | -2.10e+09 | -2.14e+09 | -2.13e+09 | -2.06e+09 | -2.14e+09 | -2.05e+09 | -2.14e+09 | -1.86e+09 | -2.05e+09 | -2.09e+09 | -2.11e+09 | -2.14e+09 | -2.14e+09 | -2.11e+09 | -2.10e+09 | -2.04e+09 | -2.14e+09 | 9.38e+03 | 1.00 |
basket_ID
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
61,241 (56.0%)
This column has a high cardinality (> 40).
- Mean ± Std
- 3.59e+04 ± 2.24e+04
- Median ± IQR
- 3.52e+04 ± 3.94e+04
- Min | Max
- 0.00 | 7.65e+04
item_00
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
70 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.03e+09 ± 1.54e+08
- Median ± IQR
- -2.12e+09 ± 1.82e+08
- Min | Max
- -2.15e+09 | -1.04e+09
item_01
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
46 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.92e+09 ± 2.63e+08
- Median ± IQR
- -2.06e+09 ± 4.74e+08
- Min | Max
- -2.14e+09 | -1.09e+09
item_02
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
57 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.98e+09 ± 1.85e+08
- Median ± IQR
- -2.09e+09 ± 3.47e+08
- Min | Max
- -2.14e+09 | -3.95e+08
item_03
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
52 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.06e+09 ± 8.25e+07
- Median ± IQR
- -2.07e+09 ± 7.25e+07
- Min | Max
- -2.15e+09 | -8.27e+08
item_04
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
63 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.02e+09 ± 6.26e+07
- Median ± IQR
- -2.05e+09 ± 6.66e+07
- Min | Max
- -2.15e+09 | -1.08e+09
item_05
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
61 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.99e+09 ± 2.14e+08
- Median ± IQR
- -2.06e+09 ± 2.47e+07
- Min | Max
- -2.14e+09 | -8.93e+08
item_06
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
67 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.77e+09 ± 3.82e+08
- Median ± IQR
- -1.99e+09 ± 6.68e+08
- Min | Max
- -2.14e+09 | -9.01e+07
item_07
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
60 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.97e+09 ± 1.38e+08
- Median ± IQR
- -2.00e+09 ± 7.90e+07
- Min | Max
- -2.14e+09 | -1.20e+09
item_08
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
64 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.98e+09 ± 1.06e+08
- Median ± IQR
- -2.02e+09 ± 2.12e+08
- Min | Max
- -2.15e+09 | -9.20e+08
item_09
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
67 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.01e+09 ± 2.29e+08
- Median ± IQR
- -2.06e+09 ± 8.91e+07
- Min | Max
- -2.14e+09 | 7.04e+08
item_10
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
60 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.02e+09 ± 8.09e+07
- Median ± IQR
- -2.04e+09 ± 1.31e+08
- Min | Max
- -2.14e+09 | 2.67e+07
item_11
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
56 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.10e+09 ± 1.06e+08
- Median ± IQR
- -2.14e+09 ± 4.89e+07
- Min | Max
- -2.14e+09 | -5.71e+08
item_12
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
58 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.04e+09 ± 8.67e+07
- Median ± IQR
- -2.06e+09 ± 1.31e+08
- Min | Max
- -2.14e+09 | -1.05e+09
item_13
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
57 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.04e+09 ± 1.47e+08
- Median ± IQR
- -2.10e+09 ± 9.61e+07
- Min | Max
- -2.15e+09 | -1.14e+09
item_14
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
60 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.98e+09 ± 1.50e+08
- Median ± IQR
- -1.99e+09 ± 2.40e+08
- Min | Max
- -2.15e+09 | -5.50e+08
item_15
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
62 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.99e+09 ± 1.23e+08
- Median ± IQR
- -2.01e+09 ± 2.11e+08
- Min | Max
- -2.15e+09 | -8.00e+08
item_16
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
66 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.04e+09 ± 1.01e+08
- Median ± IQR
- -2.06e+09 ± 5.40e+07
- Min | Max
- -2.15e+09 | -6.04e+08
item_17
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
55 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.04e+09 ± 9.10e+07
- Median ± IQR
- -2.04e+09 ± 8.40e+07
- Min | Max
- -2.15e+09 | -1.13e+09
item_18
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
68 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.00e+09 ± 9.04e+07
- Median ± IQR
- -1.96e+09 ± 1.30e+08
- Min | Max
- -2.14e+09 | -9.75e+08
item_19
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
51 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.06e+09 ± 1.05e+08
- Median ± IQR
- -2.08e+09 ± 1.06e+08
- Min | Max
- -2.15e+09 | -5.72e+08
item_20
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
57 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.01e+09 ± 2.98e+08
- Median ± IQR
- -2.10e+09 ± 4.17e+07
- Min | Max
- -2.14e+09 | -5.10e+06
item_21
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
62 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.04e+09 ± 1.01e+08
- Median ± IQR
- -2.05e+09 ± 1.36e+08
- Min | Max
- -2.14e+09 | -8.74e+08
item_22
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
56 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.99e+09 ± 1.44e+08
- Median ± IQR
- -2.06e+09 ± 2.10e+08
- Min | Max
- -2.14e+09 | -7.91e+08
item_23
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
60 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.05e+09 ± 1.31e+08
- Median ± IQR
- -2.08e+09 ± 3.95e+07
- Min | Max
- -2.15e+09 | -7.27e+08
item_24
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
61 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.01e+09 ± 1.55e+08
- Median ± IQR
- -2.09e+09 ± 1.89e+08
- Min | Max
- -2.14e+09 | -5.03e+08
item_25
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
66 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.90e+09 ± 2.06e+08
- Median ± IQR
- -1.83e+09 ± 4.25e+08
- Min | Max
- -2.14e+09 | -8.07e+08
item_26
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
70 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.95e+09 ± 1.30e+08
- Median ± IQR
- -1.84e+09 ± 2.15e+08
- Min | Max
- -2.15e+09 | -1.36e+09
item_27
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
64 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.00e+09 ± 1.69e+08
- Median ± IQR
- -2.11e+09 ± 1.69e+08
- Min | Max
- -2.15e+09 | -9.92e+08
item_28
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
74 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.05e+09 ± 1.21e+08
- Median ± IQR
- -2.12e+09 ± 1.78e+08
- Min | Max
- -2.15e+09 | -9.07e+08
item_29
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
58 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.99e+09 ± 1.21e+08
- Median ± IQR
- -1.97e+09 ± 1.53e+08
- Min | Max
- -2.15e+09 | -1.07e+09
cash_price
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
1,280 (1.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- 672. ± 714.
- Median ± IQR
- 499. ± 1.05e+03
- Min | Max
- 0.00 | 1.83e+04
make
Float64DType- Null values
- 1,273 (1.2%)
- Unique values
-
690 (0.6%)
This column has a high cardinality (> 40).
- Mean ± Std
- 254. ± 234.
- Median ± IQR
- 168. ± 478.
- Min | Max
- 0.00 | 689.
model_00
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
429 (0.4%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.92e+09 ± 2.97e+08
- Median ± IQR
- -2.07e+09 ± 4.85e+08
- Min | Max
- -2.15e+09 | 0.00
model_01
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
309 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.07e+09 ± 2.47e+08
- Median ± IQR
- -2.14e+09 ± 4.84e+07
- Min | Max
- -2.15e+09 | 0.00
model_02
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
309 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.06e+09 ± 2.32e+08
- Median ± IQR
- -2.12e+09 ± 1.11e+08
- Min | Max
- -2.15e+09 | 4.22e+07
model_03
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
311 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.03e+09 ± 2.36e+08
- Median ± IQR
- -2.10e+09 ± 1.72e+08
- Min | Max
- -2.15e+09 | 0.00
model_04
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
386 (0.4%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.00e+09 ± 2.32e+08
- Median ± IQR
- -1.99e+09 ± 1.24e+08
- Min | Max
- -2.15e+09 | 0.00
model_05
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
301 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.08e+09 ± 2.29e+08
- Median ± IQR
- -2.10e+09 ± 1.81e+07
- Min | Max
- -2.15e+09 | 8.95e+08
model_06
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
296 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.85e+09 ± 4.02e+08
- Median ± IQR
- -2.08e+09 ± 7.94e+08
- Min | Max
- -2.15e+09 | 0.00
model_07
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
329 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.00e+09 ± 2.39e+08
- Median ± IQR
- -2.09e+09 ± 2.00e+08
- Min | Max
- -2.15e+09 | 0.00
model_08
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
385 (0.4%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.96e+09 ± 2.66e+08
- Median ± IQR
- -2.07e+09 ± 3.38e+08
- Min | Max
- -2.15e+09 | 0.00
model_09
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
254 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.98e+09 ± 2.67e+08
- Median ± IQR
- -2.09e+09 ± 3.51e+08
- Min | Max
- -2.15e+09 | 0.00
model_10
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
345 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.06e+09 ± 2.33e+08
- Median ± IQR
- -2.09e+09 ± 1.59e+07
- Min | Max
- -2.15e+09 | 1.05e+09
model_11
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
318 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.07e+09 ± 2.29e+08
- Median ± IQR
- -2.10e+09 ± 4.71e+07
- Min | Max
- -2.15e+09 | 2.73e+08
model_12
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
428 (0.4%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.94e+09 ± 2.68e+08
- Median ± IQR
- -2.05e+09 ± 3.76e+08
- Min | Max
- -2.15e+09 | 0.00
model_13
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
337 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.07e+09 ± 2.27e+08
- Median ± IQR
- -2.10e+09 ± 0.00
- Min | Max
- -2.15e+09 | 0.00
model_14
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
290 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.05e+09 ± 2.35e+08
- Median ± IQR
- -2.10e+09 ± 1.36e+08
- Min | Max
- -2.15e+09 | 9.05e+07
model_15
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
321 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.02e+09 ± 2.34e+08
- Median ± IQR
- -2.03e+09 ± 1.38e+08
- Min | Max
- -2.15e+09 | 3.49e+08
model_16
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
403 (0.4%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.89e+09 ± 2.99e+08
- Median ± IQR
- -2.05e+09 ± 4.73e+08
- Min | Max
- -2.15e+09 | 0.00
model_17
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
376 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.78e+09 ± 4.85e+08
- Median ± IQR
- -2.10e+09 ± 1.00e+09
- Min | Max
- -2.15e+09 | 4.20e+08
model_18
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
352 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.03e+09 ± 2.26e+08
- Median ± IQR
- -2.05e+09 ± 7.62e+07
- Min | Max
- -2.15e+09 | 1.57e+09
model_19
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
229 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.07e+09 ± 2.33e+08
- Median ± IQR
- -2.14e+09 ± 1.15e+08
- Min | Max
- -2.15e+09 | 2.29e+08
model_20
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
372 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.98e+09 ± 2.71e+08
- Median ± IQR
- -2.10e+09 ± 3.51e+08
- Min | Max
- -2.15e+09 | 0.00
model_21
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
280 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.08e+09 ± 2.34e+08
- Median ± IQR
- -2.10e+09 ± 5.59e+07
- Min | Max
- -2.15e+09 | 1.15e+09
model_22
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
362 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.88e+09 ± 3.13e+08
- Median ± IQR
- -2.02e+09 ± 5.39e+08
- Min | Max
- -2.15e+09 | 6.53e+08
model_23
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
400 (0.4%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.91e+09 ± 3.17e+08
- Median ± IQR
- -2.07e+09 ± 5.39e+08
- Min | Max
- -2.15e+09 | 9.93e+08
model_24
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
336 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.04e+09 ± 2.33e+08
- Median ± IQR
- -2.07e+09 ± 1.49e+08
- Min | Max
- -2.15e+09 | 0.00
model_25
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
332 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.97e+09 ± 2.77e+08
- Median ± IQR
- -2.10e+09 ± 3.83e+08
- Min | Max
- -2.15e+09 | 0.00
model_26
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
354 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.05e+09 ± 2.40e+08
- Median ± IQR
- -2.09e+09 ± 5.31e+07
- Min | Max
- -2.15e+09 | 1.14e+09
model_27
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
293 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.07e+09 ± 2.31e+08
- Median ± IQR
- -2.09e+09 ± 6.08e+07
- Min | Max
- -2.15e+09 | 1.20e+09
model_28
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
364 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.07e+09 ± 2.37e+08
- Median ± IQR
- -2.10e+09 ± 4.27e+07
- Min | Max
- -2.15e+09 | 4.59e+08
model_29
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
398 (0.4%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.98e+09 ± 2.35e+08
- Median ± IQR
- -1.97e+09 ± 1.77e+08
- Min | Max
- -2.15e+09 | 1.17e+09
goods_code
Float64DType- Null values
- 0 (0.0%)
- Unique values
-
10,738 (9.8%)
This column has a high cardinality (> 40).
- Mean ± Std
- 7.91e+03 ± 3.01e+03
- Median ± IQR
- 8.72e+03 ± 3.46e+03
- Min | Max
- 0.00 | 1.07e+04
Nbr_of_prod_purchas
Float32DType- Null values
- 0 (0.0%)
- Unique values
- 19 (< 0.1%)
- Mean ± Std
- 1.05 ± 0.426
- Median ± IQR
- 1.00 ± 0.00
- Min | Max
- 1.00 | 40.0
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
| Column | Column name | dtype | Is sorted | Null values | Unique values | Mean | Std | Min | Median | Max |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | basket_ID | Float32DType | False | 0 (0.0%) | 61241 (56.0%) | 3.59e+04 | 2.24e+04 | 0.00 | 3.52e+04 | 7.65e+04 |
| 1 | item_00 | Float32DType | False | 0 (0.0%) | 70 (< 0.1%) | -2.03e+09 | 1.54e+08 | -2.15e+09 | -2.12e+09 | -1.04e+09 |
| 2 | item_01 | Float32DType | False | 0 (0.0%) | 46 (< 0.1%) | -1.92e+09 | 2.63e+08 | -2.14e+09 | -2.06e+09 | -1.09e+09 |
| 3 | item_02 | Float32DType | False | 0 (0.0%) | 57 (< 0.1%) | -1.98e+09 | 1.85e+08 | -2.14e+09 | -2.09e+09 | -3.95e+08 |
| 4 | item_03 | Float32DType | False | 0 (0.0%) | 52 (< 0.1%) | -2.06e+09 | 8.25e+07 | -2.15e+09 | -2.07e+09 | -8.27e+08 |
| 5 | item_04 | Float32DType | False | 0 (0.0%) | 63 (< 0.1%) | -2.02e+09 | 6.26e+07 | -2.15e+09 | -2.05e+09 | -1.08e+09 |
| 6 | item_05 | Float32DType | False | 0 (0.0%) | 61 (< 0.1%) | -1.99e+09 | 2.14e+08 | -2.14e+09 | -2.06e+09 | -8.93e+08 |
| 7 | item_06 | Float32DType | False | 0 (0.0%) | 67 (< 0.1%) | -1.77e+09 | 3.82e+08 | -2.14e+09 | -1.99e+09 | -9.01e+07 |
| 8 | item_07 | Float32DType | False | 0 (0.0%) | 60 (< 0.1%) | -1.97e+09 | 1.38e+08 | -2.14e+09 | -2.00e+09 | -1.20e+09 |
| 9 | item_08 | Float32DType | False | 0 (0.0%) | 64 (< 0.1%) | -1.98e+09 | 1.06e+08 | -2.15e+09 | -2.02e+09 | -9.20e+08 |
| 10 | item_09 | Float32DType | False | 0 (0.0%) | 67 (< 0.1%) | -2.01e+09 | 2.29e+08 | -2.14e+09 | -2.06e+09 | 7.04e+08 |
| 11 | item_10 | Float32DType | False | 0 (0.0%) | 60 (< 0.1%) | -2.02e+09 | 8.09e+07 | -2.14e+09 | -2.04e+09 | 2.67e+07 |
| 12 | item_11 | Float32DType | False | 0 (0.0%) | 56 (< 0.1%) | -2.10e+09 | 1.06e+08 | -2.14e+09 | -2.14e+09 | -5.71e+08 |
| 13 | item_12 | Float32DType | False | 0 (0.0%) | 58 (< 0.1%) | -2.04e+09 | 8.67e+07 | -2.14e+09 | -2.06e+09 | -1.05e+09 |
| 14 | item_13 | Float32DType | False | 0 (0.0%) | 57 (< 0.1%) | -2.04e+09 | 1.47e+08 | -2.15e+09 | -2.10e+09 | -1.14e+09 |
| 15 | item_14 | Float32DType | False | 0 (0.0%) | 60 (< 0.1%) | -1.98e+09 | 1.50e+08 | -2.15e+09 | -1.99e+09 | -5.50e+08 |
| 16 | item_15 | Float32DType | False | 0 (0.0%) | 62 (< 0.1%) | -1.99e+09 | 1.23e+08 | -2.15e+09 | -2.01e+09 | -8.00e+08 |
| 17 | item_16 | Float32DType | False | 0 (0.0%) | 66 (< 0.1%) | -2.04e+09 | 1.01e+08 | -2.15e+09 | -2.06e+09 | -6.04e+08 |
| 18 | item_17 | Float32DType | False | 0 (0.0%) | 55 (< 0.1%) | -2.04e+09 | 9.10e+07 | -2.15e+09 | -2.04e+09 | -1.13e+09 |
| 19 | item_18 | Float32DType | False | 0 (0.0%) | 68 (< 0.1%) | -2.00e+09 | 9.04e+07 | -2.14e+09 | -1.96e+09 | -9.75e+08 |
| 20 | item_19 | Float32DType | False | 0 (0.0%) | 51 (< 0.1%) | -2.06e+09 | 1.05e+08 | -2.15e+09 | -2.08e+09 | -5.72e+08 |
| 21 | item_20 | Float32DType | False | 0 (0.0%) | 57 (< 0.1%) | -2.01e+09 | 2.98e+08 | -2.14e+09 | -2.10e+09 | -5.10e+06 |
| 22 | item_21 | Float32DType | False | 0 (0.0%) | 62 (< 0.1%) | -2.04e+09 | 1.01e+08 | -2.14e+09 | -2.05e+09 | -8.74e+08 |
| 23 | item_22 | Float32DType | False | 0 (0.0%) | 56 (< 0.1%) | -1.99e+09 | 1.44e+08 | -2.14e+09 | -2.06e+09 | -7.91e+08 |
| 24 | item_23 | Float32DType | False | 0 (0.0%) | 60 (< 0.1%) | -2.05e+09 | 1.31e+08 | -2.15e+09 | -2.08e+09 | -7.27e+08 |
| 25 | item_24 | Float32DType | False | 0 (0.0%) | 61 (< 0.1%) | -2.01e+09 | 1.55e+08 | -2.14e+09 | -2.09e+09 | -5.03e+08 |
| 26 | item_25 | Float32DType | False | 0 (0.0%) | 66 (< 0.1%) | -1.90e+09 | 2.06e+08 | -2.14e+09 | -1.83e+09 | -8.07e+08 |
| 27 | item_26 | Float32DType | False | 0 (0.0%) | 70 (< 0.1%) | -1.95e+09 | 1.30e+08 | -2.15e+09 | -1.84e+09 | -1.36e+09 |
| 28 | item_27 | Float32DType | False | 0 (0.0%) | 64 (< 0.1%) | -2.00e+09 | 1.69e+08 | -2.15e+09 | -2.11e+09 | -9.92e+08 |
| 29 | item_28 | Float32DType | False | 0 (0.0%) | 74 (< 0.1%) | -2.05e+09 | 1.21e+08 | -2.15e+09 | -2.12e+09 | -9.07e+08 |
| 30 | item_29 | Float32DType | False | 0 (0.0%) | 58 (< 0.1%) | -1.99e+09 | 1.21e+08 | -2.15e+09 | -1.97e+09 | -1.07e+09 |
| 31 | cash_price | Float32DType | False | 0 (0.0%) | 1280 (1.2%) | 672. | 714. | 0.00 | 499. | 1.83e+04 |
| 32 | make | Float64DType | False | 1273 (1.2%) | 690 (0.6%) | 254. | 234. | 0.00 | 168. | 689. |
| 33 | model_00 | Float32DType | False | 0 (0.0%) | 429 (0.4%) | -1.92e+09 | 2.97e+08 | -2.15e+09 | -2.07e+09 | 0.00 |
| 34 | model_01 | Float32DType | False | 0 (0.0%) | 309 (0.3%) | -2.07e+09 | 2.47e+08 | -2.15e+09 | -2.14e+09 | 0.00 |
| 35 | model_02 | Float32DType | False | 0 (0.0%) | 309 (0.3%) | -2.06e+09 | 2.32e+08 | -2.15e+09 | -2.12e+09 | 4.22e+07 |
| 36 | model_03 | Float32DType | False | 0 (0.0%) | 311 (0.3%) | -2.03e+09 | 2.36e+08 | -2.15e+09 | -2.10e+09 | 0.00 |
| 37 | model_04 | Float32DType | False | 0 (0.0%) | 386 (0.4%) | -2.00e+09 | 2.32e+08 | -2.15e+09 | -1.99e+09 | 0.00 |
| 38 | model_05 | Float32DType | False | 0 (0.0%) | 301 (0.3%) | -2.08e+09 | 2.29e+08 | -2.15e+09 | -2.10e+09 | 8.95e+08 |
| 39 | model_06 | Float32DType | False | 0 (0.0%) | 296 (0.3%) | -1.85e+09 | 4.02e+08 | -2.15e+09 | -2.08e+09 | 0.00 |
| 40 | model_07 | Float32DType | False | 0 (0.0%) | 329 (0.3%) | -2.00e+09 | 2.39e+08 | -2.15e+09 | -2.09e+09 | 0.00 |
| 41 | model_08 | Float32DType | False | 0 (0.0%) | 385 (0.4%) | -1.96e+09 | 2.66e+08 | -2.15e+09 | -2.07e+09 | 0.00 |
| 42 | model_09 | Float32DType | False | 0 (0.0%) | 254 (0.2%) | -1.98e+09 | 2.67e+08 | -2.15e+09 | -2.09e+09 | 0.00 |
| 43 | model_10 | Float32DType | False | 0 (0.0%) | 345 (0.3%) | -2.06e+09 | 2.33e+08 | -2.15e+09 | -2.09e+09 | 1.05e+09 |
| 44 | model_11 | Float32DType | False | 0 (0.0%) | 318 (0.3%) | -2.07e+09 | 2.29e+08 | -2.15e+09 | -2.10e+09 | 2.73e+08 |
| 45 | model_12 | Float32DType | False | 0 (0.0%) | 428 (0.4%) | -1.94e+09 | 2.68e+08 | -2.15e+09 | -2.05e+09 | 0.00 |
| 46 | model_13 | Float32DType | False | 0 (0.0%) | 337 (0.3%) | -2.07e+09 | 2.27e+08 | -2.15e+09 | -2.10e+09 | 0.00 |
| 47 | model_14 | Float32DType | False | 0 (0.0%) | 290 (0.3%) | -2.05e+09 | 2.35e+08 | -2.15e+09 | -2.10e+09 | 9.05e+07 |
| 48 | model_15 | Float32DType | False | 0 (0.0%) | 321 (0.3%) | -2.02e+09 | 2.34e+08 | -2.15e+09 | -2.03e+09 | 3.49e+08 |
| 49 | model_16 | Float32DType | False | 0 (0.0%) | 403 (0.4%) | -1.89e+09 | 2.99e+08 | -2.15e+09 | -2.05e+09 | 0.00 |
| 50 | model_17 | Float32DType | False | 0 (0.0%) | 376 (0.3%) | -1.78e+09 | 4.85e+08 | -2.15e+09 | -2.10e+09 | 4.20e+08 |
| 51 | model_18 | Float32DType | False | 0 (0.0%) | 352 (0.3%) | -2.03e+09 | 2.26e+08 | -2.15e+09 | -2.05e+09 | 1.57e+09 |
| 52 | model_19 | Float32DType | False | 0 (0.0%) | 229 (0.2%) | -2.07e+09 | 2.33e+08 | -2.15e+09 | -2.14e+09 | 2.29e+08 |
| 53 | model_20 | Float32DType | False | 0 (0.0%) | 372 (0.3%) | -1.98e+09 | 2.71e+08 | -2.15e+09 | -2.10e+09 | 0.00 |
| 54 | model_21 | Float32DType | False | 0 (0.0%) | 280 (0.3%) | -2.08e+09 | 2.34e+08 | -2.15e+09 | -2.10e+09 | 1.15e+09 |
| 55 | model_22 | Float32DType | False | 0 (0.0%) | 362 (0.3%) | -1.88e+09 | 3.13e+08 | -2.15e+09 | -2.02e+09 | 6.53e+08 |
| 56 | model_23 | Float32DType | False | 0 (0.0%) | 400 (0.4%) | -1.91e+09 | 3.17e+08 | -2.15e+09 | -2.07e+09 | 9.93e+08 |
| 57 | model_24 | Float32DType | False | 0 (0.0%) | 336 (0.3%) | -2.04e+09 | 2.33e+08 | -2.15e+09 | -2.07e+09 | 0.00 |
| 58 | model_25 | Float32DType | False | 0 (0.0%) | 332 (0.3%) | -1.97e+09 | 2.77e+08 | -2.15e+09 | -2.10e+09 | 0.00 |
| 59 | model_26 | Float32DType | False | 0 (0.0%) | 354 (0.3%) | -2.05e+09 | 2.40e+08 | -2.15e+09 | -2.09e+09 | 1.14e+09 |
| 60 | model_27 | Float32DType | False | 0 (0.0%) | 293 (0.3%) | -2.07e+09 | 2.31e+08 | -2.15e+09 | -2.09e+09 | 1.20e+09 |
| 61 | model_28 | Float32DType | False | 0 (0.0%) | 364 (0.3%) | -2.07e+09 | 2.37e+08 | -2.15e+09 | -2.10e+09 | 4.59e+08 |
| 62 | model_29 | Float32DType | False | 0 (0.0%) | 398 (0.4%) | -1.98e+09 | 2.35e+08 | -2.15e+09 | -1.97e+09 | 1.17e+09 |
| 63 | goods_code | Float64DType | False | 0 (0.0%) | 10738 (9.8%) | 7.91e+03 | 3.01e+03 | 0.00 | 8.72e+03 | 1.07e+04 |
| 64 | Nbr_of_prod_purchas | Float32DType | False | 0 (0.0%) | 19 (< 0.1%) | 1.05 | 0.426 | 1.00 | 1.00 | 40.0 |
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
max_plot_columns
limit set for the TableReport during report creation.
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
max_association_columns parameter.
Please enable javascript
The skrub table reports need javascript to display correctly. If you are displaying a report in a Jupyter notebook and you see this message, you may need to re-execute the cell or to trust the notebook (button on the top right or "File > Trust notebook").
Our objective is now to aggregate this vectorized product dataframe by
"basket_ID", then to merge it on the baskets dataframe, still on
the "basket_ID".
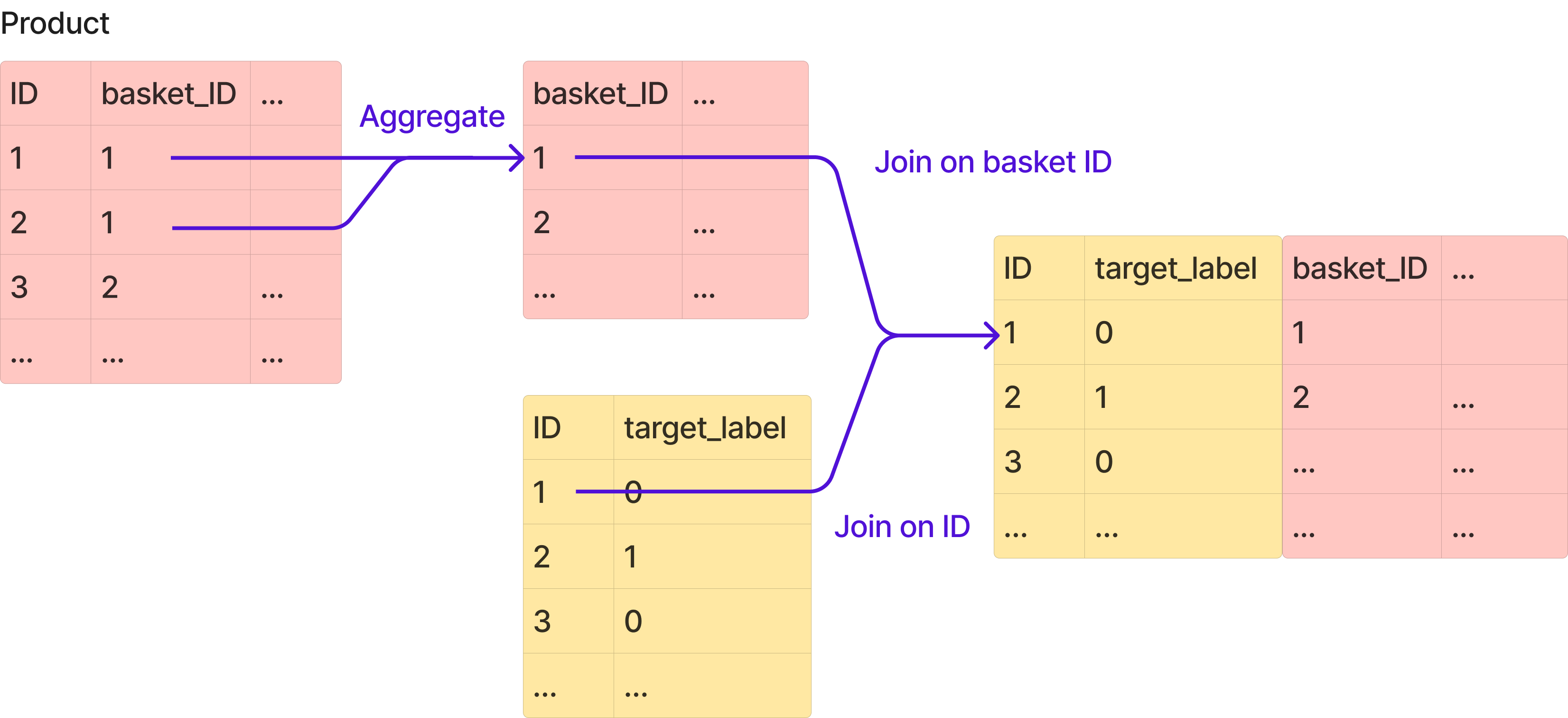
AggJoiner can help us achieve exactly this. We need to pass the product dataframe as
an auxiliary table argument to AggJoiner in __init__. The aux_key argument
represent both the columns used to groupby on, and the columns used to join on.
The basket dataframe is our main table, and we indicate the columns to join on with
main_key. Note that we pass the main table during fit, and we discuss the
limitations of this design in the conclusion at the bottom of this notebook.
The minimum (“min”) is the most appropriate operation to aggregate encodings from
MinHashEncoder, for reasons that are out of the scope of this notebook.
from skrub import AggJoiner
from skrub import selectors as s
# Skrub selectors allow us to select columns using regexes, which reduces
# the boilerplate.
minhash_cols_query = s.glob("item*") | s.glob("model*")
minhash_cols = s.select(products_transformed, minhash_cols_query).columns
agg_joiner = AggJoiner(
aux_table=products_transformed,
aux_key="basket_ID",
main_key="ID",
cols=minhash_cols,
operations=["min"],
)
baskets_products = agg_joiner.fit_transform(baskets)
TableReport(baskets_products)
| ID | fraud_flag | item_00_min | item_01_min | item_02_min | item_03_min | item_04_min | item_05_min | item_06_min | item_07_min | item_08_min | item_09_min | item_10_min | item_11_min | item_12_min | item_13_min | item_14_min | item_15_min | item_16_min | item_17_min | item_18_min | item_19_min | item_20_min | item_21_min | item_22_min | item_23_min | item_24_min | item_25_min | item_26_min | item_27_min | item_28_min | item_29_min | model_00_min | model_01_min | model_02_min | model_03_min | model_04_min | model_05_min | model_06_min | model_07_min | model_08_min | model_09_min | model_10_min | model_11_min | model_12_min | model_13_min | model_14_min | model_15_min | model_16_min | model_17_min | model_18_min | model_19_min | model_20_min | model_21_min | model_22_min | model_23_min | model_24_min | model_25_min | model_26_min | model_27_min | model_28_min | model_29_min | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 51,113 | 0 | -2.12e+09 | -2.09e+09 | -2.09e+09 | -2.10e+09 | -2.05e+09 | -2.07e+09 | -2.08e+09 | -2.01e+09 | -2.07e+09 | -2.09e+09 | -2.08e+09 | -2.14e+09 | -2.06e+09 | -2.10e+09 | -2.09e+09 | -2.12e+09 | -2.11e+09 | -2.04e+09 | -2.14e+09 | -2.13e+09 | -2.11e+09 | -2.14e+09 | -2.06e+09 | -2.08e+09 | -2.14e+09 | -2.02e+09 | -1.84e+09 | -2.12e+09 | -2.12e+09 | -2.12e+09 | -2.09e+09 | -2.14e+09 | -2.12e+09 | -2.12e+09 | -2.04e+09 | -2.14e+09 | -2.14e+09 | -2.12e+09 | -2.07e+09 | -2.07e+09 | -2.08e+09 | -2.13e+09 | -2.13e+09 | -2.11e+09 | -2.13e+09 | -2.14e+09 | -2.10e+09 | -2.14e+09 | -2.05e+09 | -2.14e+09 | -2.11e+09 | -2.09e+09 | -2.11e+09 | -2.09e+09 | -2.07e+09 | -2.10e+09 | -2.07e+09 | -2.11e+09 | -2.13e+09 | -1.99e+09 |
| 1 | 41,798 | 0 | -2.12e+09 | -1.62e+09 | -1.80e+09 | -2.07e+09 | -2.05e+09 | -2.06e+09 | -1.41e+09 | -2.00e+09 | -1.86e+09 | -2.06e+09 | -1.95e+09 | -2.14e+09 | -1.98e+09 | -2.10e+09 | -1.90e+09 | -1.89e+09 | -2.07e+09 | -2.04e+09 | -1.96e+09 | -2.03e+09 | -2.10e+09 | -2.05e+09 | -2.06e+09 | -2.08e+09 | -2.09e+09 | -1.69e+09 | -1.84e+09 | -2.12e+09 | -2.12e+09 | -1.93e+09 | -2.07e+09 | -2.09e+09 | -2.12e+09 | -2.08e+09 | -1.98e+09 | -2.12e+09 | -2.08e+09 | -2.09e+09 | -2.07e+09 | -2.11e+09 | -2.10e+09 | -2.12e+09 | -1.99e+09 | -2.11e+09 | -2.14e+09 | -2.13e+09 | -2.06e+09 | -2.13e+09 | -2.06e+09 | -2.14e+09 | -2.14e+09 | -2.14e+09 | -2.02e+09 | -2.15e+09 | -2.14e+09 | -2.10e+09 | -2.04e+09 | -2.15e+09 | -2.13e+09 | -1.96e+09 |
| 2 | 39,361 | 0 | -2.12e+09 | -1.62e+09 | -1.80e+09 | -2.07e+09 | -2.05e+09 | -2.06e+09 | -1.41e+09 | -2.00e+09 | -1.86e+09 | -2.06e+09 | -1.95e+09 | -2.14e+09 | -1.98e+09 | -2.10e+09 | -1.90e+09 | -1.89e+09 | -2.07e+09 | -2.04e+09 | -1.96e+09 | -2.03e+09 | -2.10e+09 | -2.05e+09 | -2.06e+09 | -2.08e+09 | -2.09e+09 | -1.69e+09 | -1.84e+09 | -2.12e+09 | -2.12e+09 | -1.93e+09 | -2.07e+09 | -2.14e+09 | -2.13e+09 | -2.11e+09 | -2.10e+09 | -2.10e+09 | -2.08e+09 | -2.12e+09 | -2.07e+09 | -2.09e+09 | -2.08e+09 | -2.07e+09 | -2.05e+09 | -2.10e+09 | -2.10e+09 | -2.03e+09 | -2.05e+09 | -2.13e+09 | -2.06e+09 | -2.14e+09 | -2.14e+09 | -2.14e+09 | -2.10e+09 | -2.15e+09 | -2.14e+09 | -2.11e+09 | -2.04e+09 | -2.05e+09 | -2.15e+09 | -2.11e+09 |
| 3 | 38,615 | 0 | -2.12e+09 | -2.09e+09 | -2.09e+09 | -2.10e+09 | -2.05e+09 | -2.07e+09 | -2.08e+09 | -2.01e+09 | -2.07e+09 | -2.09e+09 | -2.08e+09 | -2.14e+09 | -2.06e+09 | -2.10e+09 | -2.09e+09 | -2.12e+09 | -2.11e+09 | -2.04e+09 | -2.14e+09 | -2.13e+09 | -2.11e+09 | -2.14e+09 | -2.06e+09 | -2.08e+09 | -2.14e+09 | -2.02e+09 | -1.84e+09 | -2.12e+09 | -2.12e+09 | -2.12e+09 | -2.09e+09 | -2.12e+09 | -2.12e+09 | -2.15e+09 | -2.08e+09 | -2.14e+09 | -2.14e+09 | -2.01e+09 | -2.14e+09 | -2.05e+09 | -2.08e+09 | -2.13e+09 | -2.13e+09 | -2.11e+09 | -2.13e+09 | -2.12e+09 | -2.10e+09 | -2.14e+09 | -2.08e+09 | -2.14e+09 | -2.11e+09 | -2.12e+09 | -2.08e+09 | -2.09e+09 | -2.07e+09 | -2.10e+09 | -2.07e+09 | -2.11e+09 | -2.09e+09 | -1.99e+09 |
| 4 | 70,262 | 0 | -2.12e+09 | -1.62e+09 | -1.80e+09 | -2.07e+09 | -2.05e+09 | -2.06e+09 | -1.41e+09 | -2.00e+09 | -1.86e+09 | -2.06e+09 | -1.95e+09 | -2.14e+09 | -1.98e+09 | -2.10e+09 | -1.90e+09 | -1.89e+09 | -2.07e+09 | -2.04e+09 | -1.96e+09 | -2.03e+09 | -2.10e+09 | -2.05e+09 | -2.06e+09 | -2.08e+09 | -2.09e+09 | -1.69e+09 | -1.84e+09 | -2.12e+09 | -2.12e+09 | -1.93e+09 | -2.11e+09 | -2.09e+09 | -2.14e+09 | -2.12e+09 | -2.07e+09 | -2.10e+09 | -2.08e+09 | -2.09e+09 | -2.07e+09 | -2.14e+09 | -2.10e+09 | -2.11e+09 | -2.12e+09 | -2.10e+09 | -2.10e+09 | -2.11e+09 | -2.06e+09 | -2.13e+09 | -2.06e+09 | -2.14e+09 | -2.14e+09 | -2.14e+09 | -2.02e+09 | -2.15e+09 | -2.07e+09 | -2.10e+09 | -2.04e+09 | -2.07e+09 | -2.13e+09 | -2.01e+09 |
| 61,236 | 21,243 | 0 | -2.12e+09 | -2.09e+09 | -2.14e+09 | -2.12e+09 | -2.05e+09 | -2.09e+09 | -2.08e+09 | -2.01e+09 | -2.07e+09 | -2.09e+09 | -2.09e+09 | -2.14e+09 | -2.12e+09 | -2.10e+09 | -2.14e+09 | -2.12e+09 | -2.11e+09 | -2.14e+09 | -2.14e+09 | -2.14e+09 | -2.14e+09 | -2.14e+09 | -2.06e+09 | -2.08e+09 | -2.14e+09 | -2.02e+09 | -2.02e+09 | -2.12e+09 | -2.12e+09 | -2.12e+09 | -2.14e+09 | -2.14e+09 | -2.04e+09 | -2.14e+09 | -2.15e+09 | -2.14e+09 | -2.14e+09 | -2.14e+09 | -2.07e+09 | -2.12e+09 | -2.09e+09 | -2.10e+09 | -2.14e+09 | -2.11e+09 | -2.14e+09 | -2.13e+09 | -2.07e+09 | -2.09e+09 | -2.12e+09 | -2.14e+09 | -2.13e+09 | -2.09e+09 | -2.08e+09 | -2.03e+09 | -2.13e+09 | -2.11e+09 | -2.09e+09 | -2.09e+09 | -2.15e+09 | -2.13e+09 |
| 61,237 | 45,891 | 0 | -2.12e+09 | -1.62e+09 | -1.80e+09 | -2.07e+09 | -2.05e+09 | -2.06e+09 | -1.41e+09 | -2.00e+09 | -1.86e+09 | -2.06e+09 | -1.95e+09 | -2.14e+09 | -1.98e+09 | -2.10e+09 | -1.90e+09 | -1.89e+09 | -2.07e+09 | -2.04e+09 | -1.96e+09 | -2.03e+09 | -2.10e+09 | -2.05e+09 | -2.06e+09 | -2.08e+09 | -2.09e+09 | -1.69e+09 | -1.84e+09 | -2.12e+09 | -2.12e+09 | -1.93e+09 | -2.07e+09 | -2.14e+09 | -2.13e+09 | -2.11e+09 | -2.10e+09 | -2.10e+09 | -2.08e+09 | -2.12e+09 | -2.07e+09 | -2.09e+09 | -2.08e+09 | -2.07e+09 | -2.05e+09 | -2.10e+09 | -2.10e+09 | -2.03e+09 | -2.05e+09 | -2.13e+09 | -2.06e+09 | -2.14e+09 | -2.14e+09 | -2.14e+09 | -2.10e+09 | -2.15e+09 | -2.14e+09 | -2.11e+09 | -2.04e+09 | -2.05e+09 | -2.15e+09 | -2.11e+09 |
| 61,238 | 42,613 | 0 | -1.94e+09 | -2.14e+09 | -2.04e+09 | -2.06e+09 | -1.96e+09 | -2.12e+09 | -2.00e+09 | -2.01e+09 | -2.05e+09 | -2.13e+09 | -1.99e+09 | -2.14e+09 | -1.98e+09 | -2.07e+09 | -1.96e+09 | -2.10e+09 | -2.00e+09 | -2.02e+09 | -1.99e+09 | -2.14e+09 | -2.06e+09 | -2.11e+09 | -2.11e+09 | -2.00e+09 | -2.09e+09 | -2.14e+09 | -2.02e+09 | -2.15e+09 | -2.01e+09 | -2.08e+09 | -2.14e+09 | -2.14e+09 | -2.12e+09 | -2.14e+09 | -2.08e+09 | -2.12e+09 | -2.13e+09 | -2.12e+09 | -2.12e+09 | -2.11e+09 | -2.12e+09 | -2.14e+09 | -2.13e+09 | -2.13e+09 | -2.14e+09 | -2.14e+09 | -2.08e+09 | -2.15e+09 | -2.09e+09 | -2.14e+09 | -2.13e+09 | -2.14e+09 | -2.13e+09 | -2.15e+09 | -2.14e+09 | -2.13e+09 | -2.12e+09 | -2.15e+09 | -2.14e+09 | -2.13e+09 |
| 61,239 | 43,567 | 0 | -2.12e+09 | -1.62e+09 | -1.80e+09 | -2.07e+09 | -2.05e+09 | -2.06e+09 | -1.41e+09 | -2.00e+09 | -1.86e+09 | -2.06e+09 | -1.95e+09 | -2.14e+09 | -1.98e+09 | -2.10e+09 | -1.90e+09 | -1.89e+09 | -2.07e+09 | -2.04e+09 | -1.96e+09 | -2.03e+09 | -2.10e+09 | -2.05e+09 | -2.06e+09 | -2.08e+09 | -2.09e+09 | -1.69e+09 | -1.84e+09 | -2.12e+09 | -2.12e+09 | -1.93e+09 | -2.12e+09 | -2.14e+09 | -2.14e+09 | -2.12e+09 | -2.12e+09 | -2.10e+09 | -2.14e+09 | -2.09e+09 | -2.12e+09 | -2.14e+09 | -2.10e+09 | -2.11e+09 | -2.12e+09 | -2.13e+09 | -2.13e+09 | -2.12e+09 | -2.14e+09 | -2.13e+09 | -2.12e+09 | -2.14e+09 | -2.10e+09 | -2.14e+09 | -2.05e+09 | -2.09e+09 | -2.14e+09 | -2.11e+09 | -2.11e+09 | -2.14e+09 | -2.14e+09 | -2.10e+09 |
| 61,240 | 68,268 | 0 | -2.13e+09 | -2.10e+09 | -2.14e+09 | -2.02e+09 | -2.06e+09 | -1.88e+09 | -2.12e+09 | -2.11e+09 | -2.09e+09 | -2.06e+09 | -2.06e+09 | -2.14e+09 | -2.12e+09 | -2.10e+09 | -1.99e+09 | -2.01e+09 | -2.01e+09 | -2.13e+09 | -2.02e+09 | -2.13e+09 | -2.07e+09 | -2.14e+09 | -2.06e+09 | -2.13e+09 | -2.10e+09 | -2.11e+09 | -2.15e+09 | -1.72e+09 | -2.14e+09 | -2.07e+09 | -2.14e+09 | -2.09e+09 | -2.07e+09 | -2.12e+09 | -2.11e+09 | -2.12e+09 | -2.14e+09 | -2.09e+09 | -2.12e+09 | -2.13e+09 | -2.13e+09 | -2.14e+09 | -2.08e+09 | -2.10e+09 | -2.14e+09 | -2.13e+09 | -2.06e+09 | -2.14e+09 | -2.05e+09 | -2.14e+09 | -1.86e+09 | -2.05e+09 | -2.09e+09 | -2.11e+09 | -2.14e+09 | -2.14e+09 | -2.11e+09 | -2.10e+09 | -2.04e+09 | -2.14e+09 |
ID
Int64DType- Null values
- 0 (0.0%)
- Unique values
-
61,241 (100.0%)
This column has a high cardinality (> 40).
- Mean ± Std
- 3.82e+04 ± 2.21e+04
- Median ± IQR
- 38,158 ± 38,196
- Min | Max
- 0 | 76,543
fraud_flag
Int64DType- Null values
- 0 (0.0%)
- Unique values
- 2 (< 0.1%)
- Mean ± Std
- 0.0130 ± 0.113
- Median ± IQR
- 0 ± 0
- Min | Max
- 0 | 1
item_00_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
44 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.11e+09 ± 4.86e+07
- Median ± IQR
- -2.12e+09 ± 0.00
- Min | Max
- -2.15e+09 | -1.04e+09
item_01_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
- 36 (< 0.1%)
- Mean ± Std
- -1.97e+09 ± 2.12e+08
- Median ± IQR
- -2.09e+09 ± 4.74e+08
- Min | Max
- -2.14e+09 | -1.12e+09
item_02_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
45 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.03e+09 ± 1.50e+08
- Median ± IQR
- -2.09e+09 ± 3.47e+08
- Min | Max
- -2.14e+09 | -6.79e+08
item_03_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
- 35 (< 0.1%)
- Mean ± Std
- -2.08e+09 ± 4.49e+07
- Median ± IQR
- -2.10e+09 ± 5.19e+07
- Min | Max
- -2.15e+09 | -8.27e+08
item_04_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
44 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.05e+09 ± 3.07e+07
- Median ± IQR
- -2.05e+09 ± 0.00
- Min | Max
- -2.15e+09 | -1.08e+09
item_05_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
43 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.05e+09 ± 7.14e+07
- Median ± IQR
- -2.07e+09 ± 2.47e+07
- Min | Max
- -2.14e+09 | -8.93e+08
item_06_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
51 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.87e+09 ± 3.05e+08
- Median ± IQR
- -2.05e+09 ± 6.68e+08
- Min | Max
- -2.14e+09 | -5.96e+08
item_07_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
44 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.03e+09 ± 5.26e+07
- Median ± IQR
- -2.00e+09 ± 5.94e+07
- Min | Max
- -2.14e+09 | -1.20e+09
item_08_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
46 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.01e+09 ± 9.94e+07
- Median ± IQR
- -2.02e+09 ± 2.25e+08
- Min | Max
- -2.15e+09 | -1.46e+09
item_09_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
42 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.08e+09 ± 4.86e+07
- Median ± IQR
- -2.06e+09 ± 2.49e+07
- Min | Max
- -2.14e+09 | 7.04e+08
item_10_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
42 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.04e+09 ± 6.45e+07
- Median ± IQR
- -2.08e+09 ± 1.43e+08
- Min | Max
- -2.14e+09 | -1.07e+09
item_11_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
- 31 (< 0.1%)
- Mean ± Std
- -2.14e+09 ± 2.40e+07
- Median ± IQR
- -2.14e+09 ± 0.00
- Min | Max
- -2.14e+09 | -1.23e+09
item_12_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
- 36 (< 0.1%)
- Mean ± Std
- -2.07e+09 ± 6.45e+07
- Median ± IQR
- -2.12e+09 ± 1.31e+08
- Min | Max
- -2.14e+09 | -1.05e+09
item_13_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
- 40 (< 0.1%)
- Mean ± Std
- -2.09e+09 ± 3.61e+07
- Median ± IQR
- -2.10e+09 ± 0.00
- Min | Max
- -2.15e+09 | -1.16e+09
item_14_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
47 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.02e+09 ± 1.26e+08
- Median ± IQR
- -2.09e+09 ± 2.40e+08
- Min | Max
- -2.15e+09 | -9.70e+08
item_15_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
43 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.02e+09 ± 9.49e+07
- Median ± IQR
- -2.03e+09 ± 2.34e+08
- Min | Max
- -2.15e+09 | -8.00e+08
item_16_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
47 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.07e+09 ± 6.01e+07
- Median ± IQR
- -2.07e+09 ± 3.56e+07
- Min | Max
- -2.15e+09 | -1.34e+09
item_17_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
- 40 (< 0.1%)
- Mean ± Std
- -2.08e+09 ± 6.43e+07
- Median ± IQR
- -2.04e+09 ± 9.28e+07
- Min | Max
- -2.15e+09 | -1.33e+09
item_18_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
49 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.04e+09 ± 7.46e+07
- Median ± IQR
- -2.02e+09 ± 1.73e+08
- Min | Max
- -2.14e+09 | -1.56e+09
item_19_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
- 33 (< 0.1%)
- Mean ± Std
- -2.09e+09 ± 5.64e+07
- Median ± IQR
- -2.13e+09 ± 1.09e+08
- Min | Max
- -2.15e+09 | -1.01e+09
item_20_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
- 35 (< 0.1%)
- Mean ± Std
- -2.10e+09 ± 6.14e+07
- Median ± IQR
- -2.11e+09 ± 4.08e+07
- Min | Max
- -2.14e+09 | -5.10e+06
item_21_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
- 40 (< 0.1%)
- Mean ± Std
- -2.09e+09 ± 5.45e+07
- Median ± IQR
- -2.11e+09 ± 8.80e+07
- Min | Max
- -2.14e+09 | -8.74e+08
item_22_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
- 36 (< 0.1%)
- Mean ± Std
- -2.07e+09 ± 2.45e+07
- Median ± IQR
- -2.06e+09 ± 0.00
- Min | Max
- -2.14e+09 | -7.91e+08
item_23_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
- 39 (< 0.1%)
- Mean ± Std
- -2.09e+09 ± 4.50e+07
- Median ± IQR
- -2.08e+09 ± 6.66e+04
- Min | Max
- -2.15e+09 | -7.27e+08
item_24_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
- 37 (< 0.1%)
- Mean ± Std
- -2.10e+09 ± 4.29e+07
- Median ± IQR
- -2.09e+09 ± 3.31e+06
- Min | Max
- -2.14e+09 | -5.35e+08
item_25_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
50 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.95e+09 ± 1.83e+08
- Median ± IQR
- -2.02e+09 ± 4.25e+08
- Min | Max
- -2.14e+09 | -9.00e+08
item_26_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
53 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -1.98e+09 ± 1.25e+08
- Median ± IQR
- -2.02e+09 ± 2.60e+08
- Min | Max
- -2.15e+09 | -1.45e+09
item_27_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
41 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.06e+09 ± 1.28e+08
- Median ± IQR
- -2.12e+09 ± 1.52e+07
- Min | Max
- -2.15e+09 | -9.92e+08
item_28_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
51 (< 0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.12e+09 ± 5.13e+07
- Median ± IQR
- -2.12e+09 ± 0.00
- Min | Max
- -2.15e+09 | -1.14e+09
item_29_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
- 37 (< 0.1%)
- Mean ± Std
- -2.03e+09 ± 8.10e+07
- Median ± IQR
- -2.07e+09 ± 1.85e+08
- Min | Max
- -2.15e+09 | -1.19e+09
model_00_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
222 (0.4%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.04e+09 ± 2.46e+08
- Median ± IQR
- -2.09e+09 ± 5.50e+07
- Min | Max
- -2.15e+09 | 0.00
model_01_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
122 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.09e+09 ± 2.34e+08
- Median ± IQR
- -2.14e+09 ± 2.71e+07
- Min | Max
- -2.15e+09 | 0.00
model_02_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
145 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.09e+09 ± 2.26e+08
- Median ± IQR
- -2.12e+09 ± 8.23e+06
- Min | Max
- -2.15e+09 | 4.22e+07
model_03_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
170 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.08e+09 ± 2.27e+08
- Median ± IQR
- -2.11e+09 ± 4.11e+07
- Min | Max
- -2.15e+09 | 0.00
model_04_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
241 (0.4%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.03e+09 ± 2.29e+08
- Median ± IQR
- -2.09e+09 ± 1.35e+08
- Min | Max
- -2.15e+09 | 0.00
model_05_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
135 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.08e+09 ± 2.23e+08
- Median ± IQR
- -2.10e+09 ± 1.83e+07
- Min | Max
- -2.15e+09 | 0.00
model_06_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
165 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.05e+09 ± 2.69e+08
- Median ± IQR
- -2.08e+09 ± 5.97e+07
- Min | Max
- -2.15e+09 | 0.00
model_07_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
182 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.05e+09 ± 2.30e+08
- Median ± IQR
- -2.09e+09 ± 4.20e+07
- Min | Max
- -2.15e+09 | 0.00
model_08_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
181 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.04e+09 ± 2.43e+08
- Median ± IQR
- -2.07e+09 ± 5.20e+07
- Min | Max
- -2.15e+09 | 0.00
model_09_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
154 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.07e+09 ± 2.33e+08
- Median ± IQR
- -2.11e+09 ± 5.93e+07
- Min | Max
- -2.15e+09 | 0.00
model_10_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
187 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.07e+09 ± 2.28e+08
- Median ± IQR
- -2.09e+09 ± 1.52e+07
- Min | Max
- -2.15e+09 | 1.05e+09
model_11_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
141 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.08e+09 ± 2.24e+08
- Median ± IQR
- -2.11e+09 ± 1.82e+07
- Min | Max
- -2.15e+09 | 0.00
model_12_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
254 (0.4%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.02e+09 ± 2.44e+08
- Median ± IQR
- -2.08e+09 ± 1.36e+08
- Min | Max
- -2.15e+09 | 0.00
model_13_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
135 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.08e+09 ± 2.22e+08
- Median ± IQR
- -2.10e+09 ± 1.81e+07
- Min | Max
- -2.15e+09 | 0.00
model_14_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
133 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.09e+09 ± 2.26e+08
- Median ± IQR
- -2.13e+09 ± 4.04e+07
- Min | Max
- -2.15e+09 | 0.00
model_15_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
150 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.05e+09 ± 2.29e+08
- Median ± IQR
- -2.11e+09 ± 1.06e+08
- Min | Max
- -2.15e+09 | 0.00
model_16_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
235 (0.4%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.01e+09 ± 2.49e+08
- Median ± IQR
- -2.06e+09 ± 5.74e+07
- Min | Max
- -2.15e+09 | 0.00
model_17_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
177 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.04e+09 ± 2.95e+08
- Median ± IQR
- -2.13e+09 ± 1.72e+07
- Min | Max
- -2.15e+09 | 0.00
model_18_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
189 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.05e+09 ± 2.22e+08
- Median ± IQR
- -2.06e+09 ± 6.80e+07
- Min | Max
- -2.15e+09 | 0.00
model_19_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
86 (0.1%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.11e+09 ± 2.27e+08
- Median ± IQR
- -2.14e+09 ± 3.72e+06
- Min | Max
- -2.15e+09 | 0.00
model_20_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
203 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.07e+09 ± 2.43e+08
- Median ± IQR
- -2.11e+09 ± 3.88e+07
- Min | Max
- -2.15e+09 | 0.00
model_21_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
130 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.09e+09 ± 2.30e+08
- Median ± IQR
- -2.14e+09 ± 5.59e+07
- Min | Max
- -2.15e+09 | 1.15e+09
model_22_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
209 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.02e+09 ± 2.48e+08
- Median ± IQR
- -2.08e+09 ± 7.74e+07
- Min | Max
- -2.15e+09 | 6.53e+08
model_23_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
217 (0.4%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.05e+09 ± 2.54e+08
- Median ± IQR
- -2.11e+09 ± 8.29e+07
- Min | Max
- -2.15e+09 | 9.93e+08
model_24_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
171 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.08e+09 ± 2.27e+08
- Median ± IQR
- -2.14e+09 ± 7.00e+07
- Min | Max
- -2.15e+09 | 0.00
model_25_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
166 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.07e+09 ± 2.35e+08
- Median ± IQR
- -2.11e+09 ± 1.29e+07
- Min | Max
- -2.15e+09 | 0.00
model_26_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
170 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.06e+09 ± 2.31e+08
- Median ± IQR
- -2.09e+09 ± 2.79e+07
- Min | Max
- -2.15e+09 | 1.34e+08
model_27_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
123 (0.2%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.07e+09 ± 2.25e+08
- Median ± IQR
- -2.09e+09 ± 5.80e+07
- Min | Max
- -2.15e+09 | 0.00
model_28_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
169 (0.3%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.09e+09 ± 2.30e+08
- Median ± IQR
- -2.12e+09 ± 3.58e+07
- Min | Max
- -2.15e+09 | 2.58e+08
model_29_min
Float32DType- Null values
- 0 (0.0%)
- Unique values
-
221 (0.4%)
This column has a high cardinality (> 40).
- Mean ± Std
- -2.01e+09 ± 2.31e+08
- Median ± IQR
- -2.07e+09 ± 1.46e+08
- Min | Max
- -2.15e+09 | 2.92e+08
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
| Column | Column name | dtype | Is sorted | Null values | Unique values | Mean | Std | Min | Median | Max |
|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ID | Int64DType | False | 0 (0.0%) | 61241 (100.0%) | 3.82e+04 | 2.21e+04 | 0 | 38,158 | 76,543 |
| 1 | fraud_flag | Int64DType | False | 0 (0.0%) | 2 (< 0.1%) | 0.0130 | 0.113 | 0 | 0 | 1 |
| 2 | item_00_min | Float32DType | False | 0 (0.0%) | 44 (< 0.1%) | -2.11e+09 | 4.86e+07 | -2.15e+09 | -2.12e+09 | -1.04e+09 |
| 3 | item_01_min | Float32DType | False | 0 (0.0%) | 36 (< 0.1%) | -1.97e+09 | 2.12e+08 | -2.14e+09 | -2.09e+09 | -1.12e+09 |
| 4 | item_02_min | Float32DType | False | 0 (0.0%) | 45 (< 0.1%) | -2.03e+09 | 1.50e+08 | -2.14e+09 | -2.09e+09 | -6.79e+08 |
| 5 | item_03_min | Float32DType | False | 0 (0.0%) | 35 (< 0.1%) | -2.08e+09 | 4.49e+07 | -2.15e+09 | -2.10e+09 | -8.27e+08 |
| 6 | item_04_min | Float32DType | False | 0 (0.0%) | 44 (< 0.1%) | -2.05e+09 | 3.07e+07 | -2.15e+09 | -2.05e+09 | -1.08e+09 |
| 7 | item_05_min | Float32DType | False | 0 (0.0%) | 43 (< 0.1%) | -2.05e+09 | 7.14e+07 | -2.14e+09 | -2.07e+09 | -8.93e+08 |
| 8 | item_06_min | Float32DType | False | 0 (0.0%) | 51 (< 0.1%) | -1.87e+09 | 3.05e+08 | -2.14e+09 | -2.05e+09 | -5.96e+08 |
| 9 | item_07_min | Float32DType | False | 0 (0.0%) | 44 (< 0.1%) | -2.03e+09 | 5.26e+07 | -2.14e+09 | -2.00e+09 | -1.20e+09 |
| 10 | item_08_min | Float32DType | False | 0 (0.0%) | 46 (< 0.1%) | -2.01e+09 | 9.94e+07 | -2.15e+09 | -2.02e+09 | -1.46e+09 |
| 11 | item_09_min | Float32DType | False | 0 (0.0%) | 42 (< 0.1%) | -2.08e+09 | 4.86e+07 | -2.14e+09 | -2.06e+09 | 7.04e+08 |
| 12 | item_10_min | Float32DType | False | 0 (0.0%) | 42 (< 0.1%) | -2.04e+09 | 6.45e+07 | -2.14e+09 | -2.08e+09 | -1.07e+09 |
| 13 | item_11_min | Float32DType | False | 0 (0.0%) | 31 (< 0.1%) | -2.14e+09 | 2.40e+07 | -2.14e+09 | -2.14e+09 | -1.23e+09 |
| 14 | item_12_min | Float32DType | False | 0 (0.0%) | 36 (< 0.1%) | -2.07e+09 | 6.45e+07 | -2.14e+09 | -2.12e+09 | -1.05e+09 |
| 15 | item_13_min | Float32DType | False | 0 (0.0%) | 40 (< 0.1%) | -2.09e+09 | 3.61e+07 | -2.15e+09 | -2.10e+09 | -1.16e+09 |
| 16 | item_14_min | Float32DType | False | 0 (0.0%) | 47 (< 0.1%) | -2.02e+09 | 1.26e+08 | -2.15e+09 | -2.09e+09 | -9.70e+08 |
| 17 | item_15_min | Float32DType | False | 0 (0.0%) | 43 (< 0.1%) | -2.02e+09 | 9.49e+07 | -2.15e+09 | -2.03e+09 | -8.00e+08 |
| 18 | item_16_min | Float32DType | False | 0 (0.0%) | 47 (< 0.1%) | -2.07e+09 | 6.01e+07 | -2.15e+09 | -2.07e+09 | -1.34e+09 |
| 19 | item_17_min | Float32DType | False | 0 (0.0%) | 40 (< 0.1%) | -2.08e+09 | 6.43e+07 | -2.15e+09 | -2.04e+09 | -1.33e+09 |
| 20 | item_18_min | Float32DType | False | 0 (0.0%) | 49 (< 0.1%) | -2.04e+09 | 7.46e+07 | -2.14e+09 | -2.02e+09 | -1.56e+09 |
| 21 | item_19_min | Float32DType | False | 0 (0.0%) | 33 (< 0.1%) | -2.09e+09 | 5.64e+07 | -2.15e+09 | -2.13e+09 | -1.01e+09 |
| 22 | item_20_min | Float32DType | False | 0 (0.0%) | 35 (< 0.1%) | -2.10e+09 | 6.14e+07 | -2.14e+09 | -2.11e+09 | -5.10e+06 |
| 23 | item_21_min | Float32DType | False | 0 (0.0%) | 40 (< 0.1%) | -2.09e+09 | 5.45e+07 | -2.14e+09 | -2.11e+09 | -8.74e+08 |
| 24 | item_22_min | Float32DType | False | 0 (0.0%) | 36 (< 0.1%) | -2.07e+09 | 2.45e+07 | -2.14e+09 | -2.06e+09 | -7.91e+08 |
| 25 | item_23_min | Float32DType | False | 0 (0.0%) | 39 (< 0.1%) | -2.09e+09 | 4.50e+07 | -2.15e+09 | -2.08e+09 | -7.27e+08 |
| 26 | item_24_min | Float32DType | False | 0 (0.0%) | 37 (< 0.1%) | -2.10e+09 | 4.29e+07 | -2.14e+09 | -2.09e+09 | -5.35e+08 |
| 27 | item_25_min | Float32DType | False | 0 (0.0%) | 50 (< 0.1%) | -1.95e+09 | 1.83e+08 | -2.14e+09 | -2.02e+09 | -9.00e+08 |
| 28 | item_26_min | Float32DType | False | 0 (0.0%) | 53 (< 0.1%) | -1.98e+09 | 1.25e+08 | -2.15e+09 | -2.02e+09 | -1.45e+09 |
| 29 | item_27_min | Float32DType | False | 0 (0.0%) | 41 (< 0.1%) | -2.06e+09 | 1.28e+08 | -2.15e+09 | -2.12e+09 | -9.92e+08 |
| 30 | item_28_min | Float32DType | False | 0 (0.0%) | 51 (< 0.1%) | -2.12e+09 | 5.13e+07 | -2.15e+09 | -2.12e+09 | -1.14e+09 |
| 31 | item_29_min | Float32DType | False | 0 (0.0%) | 37 (< 0.1%) | -2.03e+09 | 8.10e+07 | -2.15e+09 | -2.07e+09 | -1.19e+09 |
| 32 | model_00_min | Float32DType | False | 0 (0.0%) | 222 (0.4%) | -2.04e+09 | 2.46e+08 | -2.15e+09 | -2.09e+09 | 0.00 |
| 33 | model_01_min | Float32DType | False | 0 (0.0%) | 122 (0.2%) | -2.09e+09 | 2.34e+08 | -2.15e+09 | -2.14e+09 | 0.00 |
| 34 | model_02_min | Float32DType | False | 0 (0.0%) | 145 (0.2%) | -2.09e+09 | 2.26e+08 | -2.15e+09 | -2.12e+09 | 4.22e+07 |
| 35 | model_03_min | Float32DType | False | 0 (0.0%) | 170 (0.3%) | -2.08e+09 | 2.27e+08 | -2.15e+09 | -2.11e+09 | 0.00 |
| 36 | model_04_min | Float32DType | False | 0 (0.0%) | 241 (0.4%) | -2.03e+09 | 2.29e+08 | -2.15e+09 | -2.09e+09 | 0.00 |
| 37 | model_05_min | Float32DType | False | 0 (0.0%) | 135 (0.2%) | -2.08e+09 | 2.23e+08 | -2.15e+09 | -2.10e+09 | 0.00 |
| 38 | model_06_min | Float32DType | False | 0 (0.0%) | 165 (0.3%) | -2.05e+09 | 2.69e+08 | -2.15e+09 | -2.08e+09 | 0.00 |
| 39 | model_07_min | Float32DType | False | 0 (0.0%) | 182 (0.3%) | -2.05e+09 | 2.30e+08 | -2.15e+09 | -2.09e+09 | 0.00 |
| 40 | model_08_min | Float32DType | False | 0 (0.0%) | 181 (0.3%) | -2.04e+09 | 2.43e+08 | -2.15e+09 | -2.07e+09 | 0.00 |
| 41 | model_09_min | Float32DType | False | 0 (0.0%) | 154 (0.3%) | -2.07e+09 | 2.33e+08 | -2.15e+09 | -2.11e+09 | 0.00 |
| 42 | model_10_min | Float32DType | False | 0 (0.0%) | 187 (0.3%) | -2.07e+09 | 2.28e+08 | -2.15e+09 | -2.09e+09 | 1.05e+09 |
| 43 | model_11_min | Float32DType | False | 0 (0.0%) | 141 (0.2%) | -2.08e+09 | 2.24e+08 | -2.15e+09 | -2.11e+09 | 0.00 |
| 44 | model_12_min | Float32DType | False | 0 (0.0%) | 254 (0.4%) | -2.02e+09 | 2.44e+08 | -2.15e+09 | -2.08e+09 | 0.00 |
| 45 | model_13_min | Float32DType | False | 0 (0.0%) | 135 (0.2%) | -2.08e+09 | 2.22e+08 | -2.15e+09 | -2.10e+09 | 0.00 |
| 46 | model_14_min | Float32DType | False | 0 (0.0%) | 133 (0.2%) | -2.09e+09 | 2.26e+08 | -2.15e+09 | -2.13e+09 | 0.00 |
| 47 | model_15_min | Float32DType | False | 0 (0.0%) | 150 (0.2%) | -2.05e+09 | 2.29e+08 | -2.15e+09 | -2.11e+09 | 0.00 |
| 48 | model_16_min | Float32DType | False | 0 (0.0%) | 235 (0.4%) | -2.01e+09 | 2.49e+08 | -2.15e+09 | -2.06e+09 | 0.00 |
| 49 | model_17_min | Float32DType | False | 0 (0.0%) | 177 (0.3%) | -2.04e+09 | 2.95e+08 | -2.15e+09 | -2.13e+09 | 0.00 |
| 50 | model_18_min | Float32DType | False | 0 (0.0%) | 189 (0.3%) | -2.05e+09 | 2.22e+08 | -2.15e+09 | -2.06e+09 | 0.00 |
| 51 | model_19_min | Float32DType | False | 0 (0.0%) | 86 (0.1%) | -2.11e+09 | 2.27e+08 | -2.15e+09 | -2.14e+09 | 0.00 |
| 52 | model_20_min | Float32DType | False | 0 (0.0%) | 203 (0.3%) | -2.07e+09 | 2.43e+08 | -2.15e+09 | -2.11e+09 | 0.00 |
| 53 | model_21_min | Float32DType | False | 0 (0.0%) | 130 (0.2%) | -2.09e+09 | 2.30e+08 | -2.15e+09 | -2.14e+09 | 1.15e+09 |
| 54 | model_22_min | Float32DType | False | 0 (0.0%) | 209 (0.3%) | -2.02e+09 | 2.48e+08 | -2.15e+09 | -2.08e+09 | 6.53e+08 |
| 55 | model_23_min | Float32DType | False | 0 (0.0%) | 217 (0.4%) | -2.05e+09 | 2.54e+08 | -2.15e+09 | -2.11e+09 | 9.93e+08 |
| 56 | model_24_min | Float32DType | False | 0 (0.0%) | 171 (0.3%) | -2.08e+09 | 2.27e+08 | -2.15e+09 | -2.14e+09 | 0.00 |
| 57 | model_25_min | Float32DType | False | 0 (0.0%) | 166 (0.3%) | -2.07e+09 | 2.35e+08 | -2.15e+09 | -2.11e+09 | 0.00 |
| 58 | model_26_min | Float32DType | False | 0 (0.0%) | 170 (0.3%) | -2.06e+09 | 2.31e+08 | -2.15e+09 | -2.09e+09 | 1.34e+08 |
| 59 | model_27_min | Float32DType | False | 0 (0.0%) | 123 (0.2%) | -2.07e+09 | 2.25e+08 | -2.15e+09 | -2.09e+09 | 0.00 |
| 60 | model_28_min | Float32DType | False | 0 (0.0%) | 169 (0.3%) | -2.09e+09 | 2.30e+08 | -2.15e+09 | -2.12e+09 | 2.58e+08 |
| 61 | model_29_min | Float32DType | False | 0 (0.0%) | 221 (0.4%) | -2.01e+09 | 2.31e+08 | -2.15e+09 | -2.07e+09 | 2.92e+08 |
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
max_plot_columns
limit set for the TableReport during report creation.
No columns match the selected filter: . You can change the column filter in the dropdown menu above.
max_association_columns parameter.
Please enable javascript
The skrub table reports need javascript to display correctly. If you are displaying a report in a Jupyter notebook and you see this message, you may need to re-execute the cell or to trust the notebook (button on the top right or "File > Trust notebook").
Now that we understand how to use the AggJoiner, we can now assemble our pipeline by
chaining two AggJoiner together:
the first one to deal with the
MinHashEncodervectors as we just sawthe second one to deal with the all the other columns
For the second AggJoiner, we use the mean, standard deviation, minimum and maximum
operations to extract a representative summary of each distribution.
DropCols is another skrub transformer which removes the “ID” column, which doesn’t
bring any information after the joining operation.
from scipy.stats import loguniform, randint
from sklearn.ensemble import HistGradientBoostingClassifier
from sklearn.pipeline import make_pipeline
from skrub import DropCols
model = make_pipeline(
AggJoiner(
aux_table=products_transformed,
aux_key="basket_ID",
main_key="ID",
cols=minhash_cols,
operations=["min"],
),
AggJoiner(
aux_table=products_transformed,
aux_key="basket_ID",
main_key="ID",
cols=["make", "goods_code", "cash_price", "Nbr_of_prod_purchas"],
operations=["sum", "mean", "std", "min", "max"],
),
DropCols(["ID"]),
HistGradientBoostingClassifier(),
)
model
Pipeline(steps=[('aggjoiner-1',
AggJoiner(aux_key='basket_ID',
aux_table= basket_ID item_00 ... goods_code Nbr_of_prod_purchas
1 51113.0 -2.119082e+09 ... 8255.0 1.0
9 41798.0 -2.119082e+09 ... 8720.0 1.0
11 39361.0 -2.119082e+09 ... 8716.0 1.0
15 38615.0 -2.119082e+09 ... 8260.0 1.0
16 70262.0 -2.119082e+09 ... 10690.0 1.0
... ... ... ... ... ...
163352 42613.0 -1.944861e+09 ... 2190.0 1.0
163353...
163354 43567.0 -2.119082e+09 ... 10020.0 1.0
163355 43567.0 -2.119082e+09 ... 7790.0 1.0
163356 68268.0 -2.128260e+09 ... 9377.0 1.0
[109380 rows x 65 columns],
cols=['make', 'goods_code', 'cash_price',
'Nbr_of_prod_purchas'],
main_key='ID',
operations=['sum', 'mean', 'std', 'min', 'max'])),
('dropcols', DropCols(cols=['ID'])),
('histgradientboostingclassifier',
HistGradientBoostingClassifier())])
We tune the hyper-parameters of the HistGradientBoostingClassifier model using RandomizedSearchCV.
By default, the HistGradientBoostingClassifier applies early stopping when there are at least 10_000
samples so we don’t need to explicitly tune the number of trees (max_iter).
Therefore we set this at a very high level of 1_000. We increase
n_iter_no_change to make sure early stopping does not kick in too early.
from time import time
from sklearn.model_selection import RandomizedSearchCV
param_distributions = dict(
histgradientboostingclassifier__learning_rate=loguniform(1e-2, 5e-1),
histgradientboostingclassifier__min_samples_leaf=randint(2, 64),
histgradientboostingclassifier__max_leaf_nodes=[None, 10, 30, 60, 90],
histgradientboostingclassifier__n_iter_no_change=[50],
histgradientboostingclassifier__max_iter=[1000],
)
tic = time()
search = RandomizedSearchCV(
model,
param_distributions,
scoring="neg_log_loss",
refit=False,
n_iter=10,
cv=3,
verbose=1,
).fit(X_train, y_train)
print(f"This operation took {time() - tic:.1f}s")
Fitting 3 folds for each of 10 candidates, totalling 30 fits
This operation took 56.5s
The best hyper parameters are:
histgradientboostingclassifier__learning_rate 0.049735
histgradientboostingclassifier__max_iter 1000.000000
histgradientboostingclassifier__max_leaf_nodes 10.000000
histgradientboostingclassifier__min_samples_leaf 48.000000
histgradientboostingclassifier__n_iter_no_change 50.000000
dtype: float64
To benchmark our performance, we plot the log loss of our model on the test set against the log loss of a dummy model that always output the observed probability of the two classes.
As this dataset is extremely imbalanced, this dummy model should be a good baseline.
The vertical bar represents one standard deviation around the mean of the cross validation log-loss.
import seaborn as sns
from matplotlib import pyplot as plt
from sklearn.dummy import DummyClassifier
from sklearn.metrics import log_loss
results = search.cv_results_
best_idx = search.best_index_
log_loss_model_mean = -results["mean_test_score"][best_idx]
log_loss_model_std = results["std_test_score"][best_idx]
dummy = DummyClassifier(strategy="prior").fit(X_train, y_train)
y_proba_dummy = dummy.predict_proba(X_test)
log_loss_dummy = log_loss(y_true=y_test, y_pred=y_proba_dummy)
fig, ax = plt.subplots()
ax.bar(
height=[log_loss_model_mean, log_loss_dummy],
x=["AggJoiner model", "Dummy"],
color=["C0", "C4"],
)
for container in ax.containers:
ax.bar_label(container, padding=4)
ax.vlines(
x="AggJoiner model",
ymin=log_loss_model_mean - log_loss_model_std,
ymax=log_loss_model_mean + log_loss_model_std,
linestyle="-",
linewidth=1,
color="k",
)
sns.despine()
ax.set_title("Log loss (lower is better)")
Text(0.5, 1.0, 'Log loss (lower is better)')
Conclusion#
With AggJoiner, you can bring the aggregation and joining operations within a
sklearn pipeline, and train models more efficiently.
One known limitation of both the AggJoiner and Joiner is that the auxiliary data
to join is passed during the __init__ method instead of the fit method, and
is therefore fixed once the model has been trained.
This limitation causes two main issues:
1. Bigger model serialization: Since the dataset has to be pickled along with the model, it can result in a massive file size on disk.
2. Inflexibility with new, unseen data in a production environment: To use new
auxiliary data, you would need to replace the auxiliary table in the AggJoiner that
was used during fit with the updated data, which is a rather hacky approach.
These limitations will be addressed later in skrub.
Total running time of the script: (1 minutes 34.948 seconds)