
StringEncoder#
- class skrub.StringEncoder(n_components=30, vectorizer='tfidf', ngram_range=(3, 4), analyzer='char_wb', stop_words=None, random_state=None, vocabulary=None)[source]#
Encode string features by using tf-idf vectorization and truncated singular value decomposition (SVD).
A note on using single column transformations
StringEncoderis a type of single column transformation . Unlike most scikit-learn estimators, itsfit,transformandfit_transformmethods expect a single column (e.g. Series) not a full dataframe. To apply this transformer to one or more columns in a dataframe, use it in aApplyToColsor aTableVectorizer.To apply to all columns:
ApplyToCols(StringEncoder())
To apply to selected columns:
ApplyToCols(StringEncoder(), cols=['col_name_1', 'col_name_2'])
First, apply a tf-idf vectorization of the text, then reduce the dimensionality with a truncated SVD with the given number of parameters.
New features will be named
{col_name}_{component}if the series has a name, andtsvd_{component}if it does not.- Parameters:
- n_components
int, default=30 Number of components to be used for the singular value decomposition (SVD). Must be a positive integer.
- vectorizer
str, “tfidf” or “hashing”, default=”tfidf” Vectorizer to apply to the strings, either tfidf or hashing for scikit-learn TfidfVectorizer or HashingVectorizer respectively.
- ngram_range
tupleof (int,int) pairs, default=(3,4) The lower and upper boundary of the range of n-values for different n-grams to be extracted. All values of n such that min_n <= n <= max_n will be used. For example an
ngram_rangeof(1, 1)means only unigrams,(1, 2)means unigrams and bigrams, and(2, 2)means only bigrams.- analyzer
str, “char”, “word” or “char_wb”, default=”char_wb” Whether the feature should be made of word or character n-grams. Option
char_wbcreates character n-grams only from text inside word boundaries; n-grams at the edges of words are padded with space.- stop_words{‘english’},
list, default=None If ‘english’, a built-in stop word list for English is used. There are several known issues with ‘english’ and you should consider an alternative (see Using stop words).
If a list, that list is assumed to contain stop words, all of which will be removed from the resulting tokens. Only applies if
analyzer == 'word'.If None, no stop words will be used.
- random_state
int,RandomStateinstance orNone, default=None Used during randomized svd. Pass an int for reproducible results across multiple function calls.
- vocabularyMapping or iterable, default=None
In case of “tfidf” vectorizer, the vocabulary mapping passed to the vectorizer. Either a Mapping (e.g., a dict) where keys are terms and values are indices in the feature matrix, or an iterable over terms.
- n_components
- Attributes:
See also
MinHashEncoderEncode string columns as a numeric array with the minhash method.
GapEncoderEncode string columns by constructing latent topics.
TextEncoderEncode string columns using pre-trained language models.
Notes
Skrub provides
StringEncoderas a simple interface to perform Latent Semantic Analysis (LSA). As such, it doesn’t support all hyper-parameters exposed by the underlying {TfidfVectorizer,HashingVectorizer} andTruncatedSVD. If you need more flexibility than the proposed hyper-parameters ofStringEncoder, you must create your own LSA using scikit-learnPipeline, such as:>>> from sklearn.pipeline import make_pipeline >>> from sklearn.feature_extraction.text import TfidfVectorizer >>> from sklearn.decomposition import TruncatedSVD
>>> make_pipeline(TfidfVectorizer(max_df=300), TruncatedSVD()) Pipeline(steps=[('tfidfvectorizer', TfidfVectorizer(max_df=300)), ('truncatedsvd', TruncatedSVD())])
Examples
>>> import pandas as pd >>> from skrub import StringEncoder
We will encode the comments using 2 components:
>>> enc = StringEncoder(n_components=2) >>> X = pd.Series([ ... "The professor snatched a good interview out of the jaws of these questions.", ... "Bookmarking this to watch later.", ... "When you don't know the lyrics of the song except the chorus", ... ], name='video comments')
>>> enc.fit_transform(X) video comments_0 video comments_1 0 1.322973 -0.163070 1 0.379688 1.659319 2 1.306400 -0.317120
Methods
fit(column[, y])Fit the transformer.
fit_transform(X[, y])Fit the encoder and transform a column.
get_feature_names_out([input_features])Return a list of features generated by the transformer.
get_params([deep])Get parameters for this estimator.
set_output(*[, transform])Set output container.
set_params(**params)Set the parameters of this estimator.
transform(X)Transform a column.
- fit(column, y=None, **kwargs)[source]#
Fit the transformer.
This default implementation simply calls
fit_transform()and returnsself.Subclasses should implement
fit_transformandtransform.- Parameters:
- columna pandas or polars
Series Unlike most scikit-learn transformers, single-column transformers transform a single column, not a whole dataframe.
- ycolumn or dataframe
Prediction targets.
- **kwargs
Extra named arguments are passed to
self.fit_transform().
- columna pandas or polars
- Returns:
- self
The fitted transformer.
- fit_transform(X, y=None)[source]#
Fit the encoder and transform a column.
- Parameters:
- XPandas or Polars series
The column to transform.
- y
None Unused. Here for compatibility with scikit-learn.
- Returns:
- X_out: Pandas or Polars dataframe with shape (len(X), tsvd_n_components)
The embedding representation of the input.
- get_feature_names_out(input_features=None)[source]#
Return a list of features generated by the transformer.
Each feature has format
{input_name}_{n_component}whereinput_nameis the name of the input column, or a default name for the encoder, andn_componentis the idx of the specific feature.
- set_output(*, transform=None)[source]#
Set output container.
See Introducing the set_output API for an example on how to use the API.
- Parameters:
- transform{“default”, “pandas”, “polars”}, default=None
Configure output of transform and fit_transform.
“default”: Default output format of a transformer
“pandas”: DataFrame output
“polars”: Polars output
None: Transform configuration is unchanged
Added in version 1.4: “polars” option was added.
- Returns:
- selfestimator instance
Estimator instance.
- set_params(**params)[source]#
Set the parameters of this estimator.
The method works on simple estimators as well as on nested objects (such as
Pipeline). The latter have parameters of the form<component>__<parameter>so that it’s possible to update each component of a nested object.- Parameters:
- **params
dict Estimator parameters.
- **params
- Returns:
- selfestimator instance
Estimator instance.
Gallery examples#

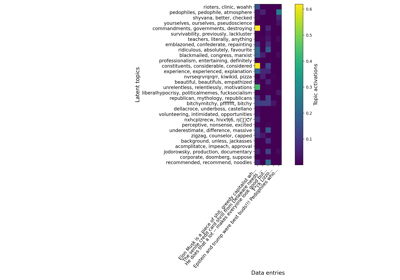
Various string encoders: a sentiment analysis example

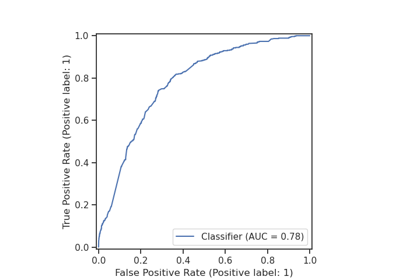
Multiples tables: building machine learning pipelines with DataOps
